5. 次世代ルーティングアーキテクチャに関する研究
5.1 省電力ルータアーキテクチャに関する研究
5.1.1 省電力ルータが存在する環境における利用可能性帯域計測手法の改善に関する研究
近年,ネットワークトラヒックの増加に伴うネットワーク機器の消費電力の増加が問題となっている.経済産業省の試算によると,国内のルータを含むネットワーク機器の総消費電力は,2006 年度の約80 億kWh から2025 年度には約1033 億kWh と,およそ13 倍に増加すると指摘されている.この問題に対して,ネットワーク負荷に応じてルータ処理性能やリンク速度の動的な変更を行うことにより,省電力を図る技術に関する研究が行われている.しかし,そのような省電力ルータがネットワーク内に存在すると,ネットワーク負荷に応じてエンド端末間パスの物理帯域が変動するため,従来提案されているエンド間利用可能帯域計測手法の計測精度が劣化すると考えられる.また,帯域計測のために発生するネットワーク負荷により,省電力ルータが十分に省電力効果を発揮できない可能性がある.
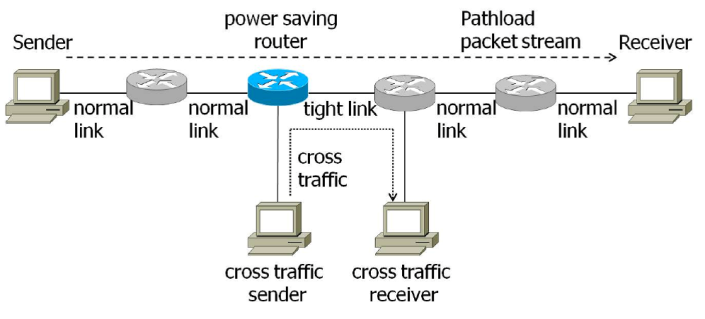
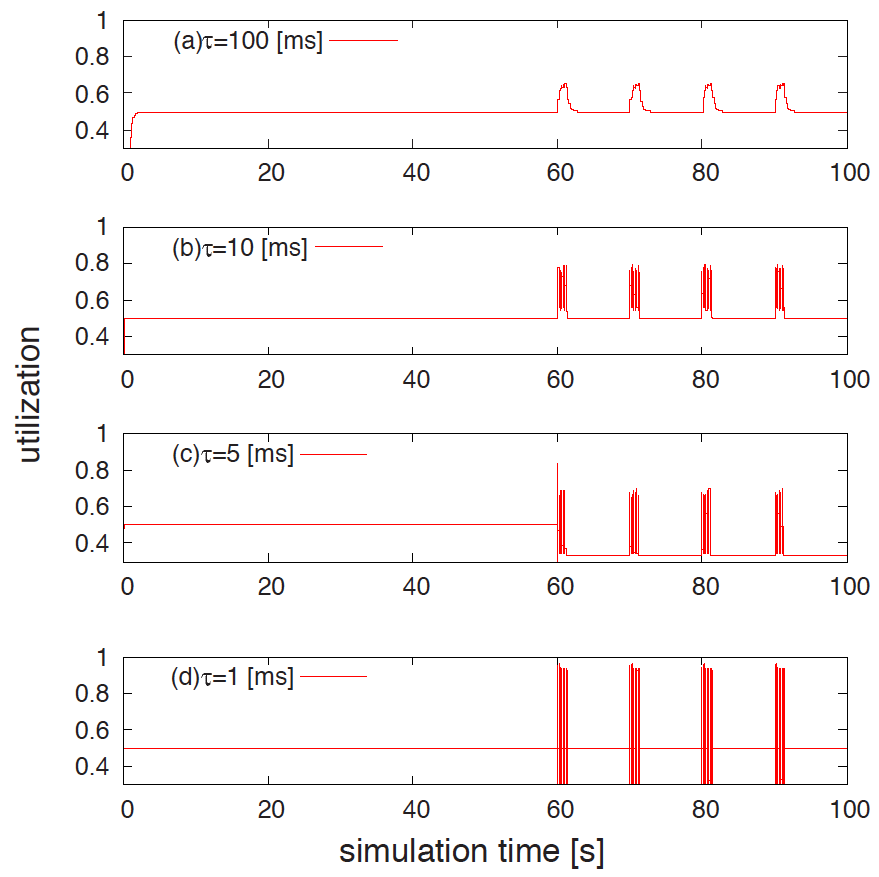
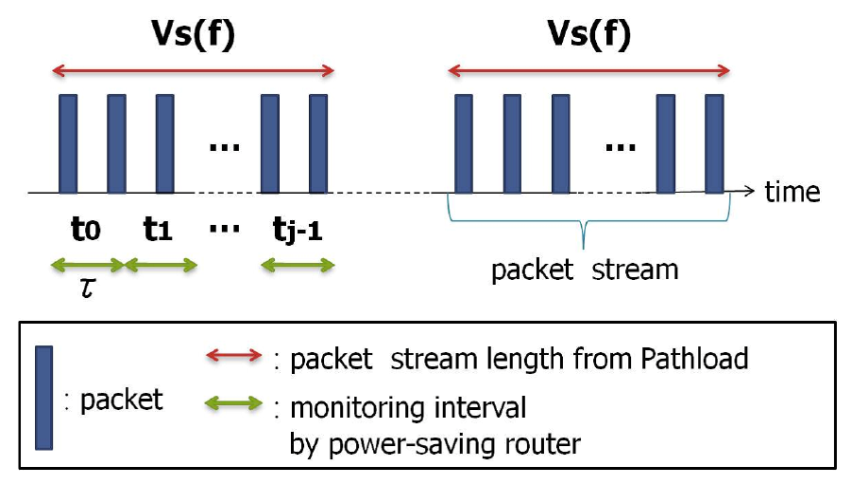
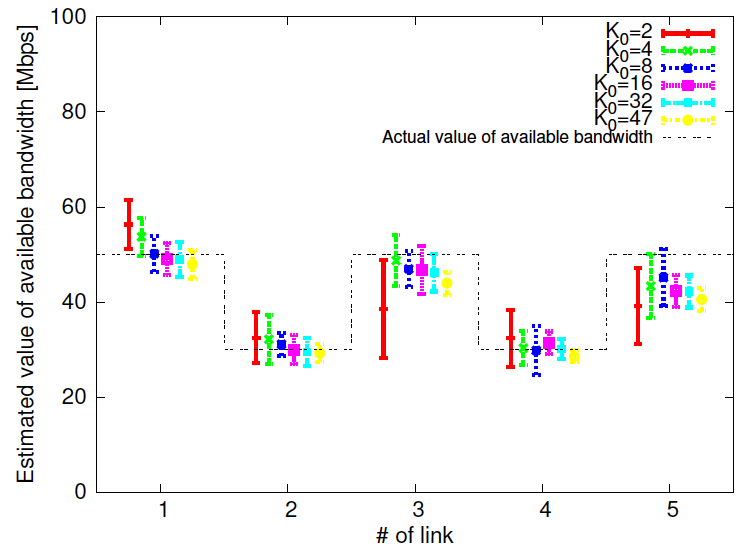
そこで本研究では,リンクの物理帯域を動的に変化させる省電力ルータがネットワークに存在する環境における,エンド間利用可能帯域計測手法Pathload の性能評価を行い,利用可能帯域計測と省電力ルータが相互に及ぼす影響を明らかにする.また,Pathload が省電力ルータに与えるトラヒック負荷を解析的に明らかにした.その結果,計測負荷によって省電力ルータが物理帯域を増加させた場合,省電力動作中の物理帯域を基準とした利用可能帯域を計測することが困難になることを示した.また,その結果に基いて,計測手法のパラメータを調整することにより,省電力ルータに影響を与えない計測を行うことが可能であることを示した.
[関連発表論文]
- Daisuke Kobayashi, Go Hasegawa, and Masayuki Murata, “Evaluation and improvement of end-to-end bandwidth measurement method for power-saving routers,” in Proceedings of 2012 Annual IEEE Communication Quality and Reliability Workshop (CQR 2012), May 2012. (Best Paper Award)
5.2 コンテンツセントリックネットワークに関する研究
将来ネットワークにおいて解決すべき課題において重要なものの一つがコンテンツセントリック(コンテンツ指向型)ネットワークである.これまでのインターネットでは,通信は「誰,あるいはどこ(who, or where)」にもとづいて行われてきた.これは,インターネットが元々コンピュータ間の通信を実現するためのものであり,指定された相手にサービスや処理を依頼する,という通信形態を考えると自然な発想であると言える.しかしながら,爆発する情報量と情報流通の高度化,さらに近年クラウドサービスなどに代表されるネットワークを含めたサービス自体の抽象化の概念が導入されつつある.すなわち,エンドユーザに対してはサービス自体が明示されるだけで,具体的にネットワーク上のどのノードが何のサービスを提供するかは隠匿されている.その結果,現在のコミュニケーションは「何(what)」を主体として行われることが一般的である.このようにコミュニケーション形態が旧来のノード指向型からデータ指向型へと変化している現在および将来において,ネットワークも従来の who, where から what にもとづいた通信を提供するように発展することが大いに期待されている.これをコンテンツセントリックネットワーク (Content Centric Networking; CCN),あるいは情報セントリックネットワークと呼ぶ.
コンテンツセントリックネットワークへの移行は従来のIPネットワークの通信パラダイムの抜本的に変革するものであり,実現にはさまざまな課題が存在する.本研究では,コンテンツセントリックネットワーク実現に向けた課題解決を目標とし,ハードウェアアーキテクチャ,キャッシュ配置,およびルーティングアーキテクチャについて取り組んでいる.
5.2.1 コンテンツセントリックネットワーク実現のためのハードウェア最適化に関する研究
本研究では CCN 実現の第一段階として,ドメイン名(FQDN)にもとづくルーティングアーキテクチャについて検討を行った.具体的には,ドメイン名をアドレスとしたレイヤ3ルーティング実現のためのルーティングトポロジ構築,ハードウェア資源割り当て,およびドメイン名の分散格納手法に関してそれぞれ提案し,現在登録されている全 FQDN をルータに格納するために必要となるハードウェア資源量,およびルータ数に関する定量評価を行った.その結果,約6.6億個のFQDNを分散格納するのに必要なルータ数は現時点で入手可能はハードウェア資源(TCAM)をしても,1000台オーダ程度で可能であることを示した.ただし,FQDNによるルーティングを行うための論理トポロジー上のルータは,実際に配置されている物理トポロジーのルータとの適切なマッピングが行わなければ,論理トポロジーと物理トポロジーの間に不整合が生じることになる.また,検索効率を向上させるためには,位置情報だけでなく FQDN のアクセス頻度を考慮したルーティングテーブルの再構成が行われることが望ましい.以上の点を考慮し,本研究では名前のアクセス頻度を考慮した論理・物理トポロジマッピング,およびそれを実現するためのルーティングテーブルの再構成のアルゴリズムを提案した.提案方式を用いることで,アクセス頻度や物理情報を考慮しない場合と比較して FQDN の検索効率の向上が確認できた.
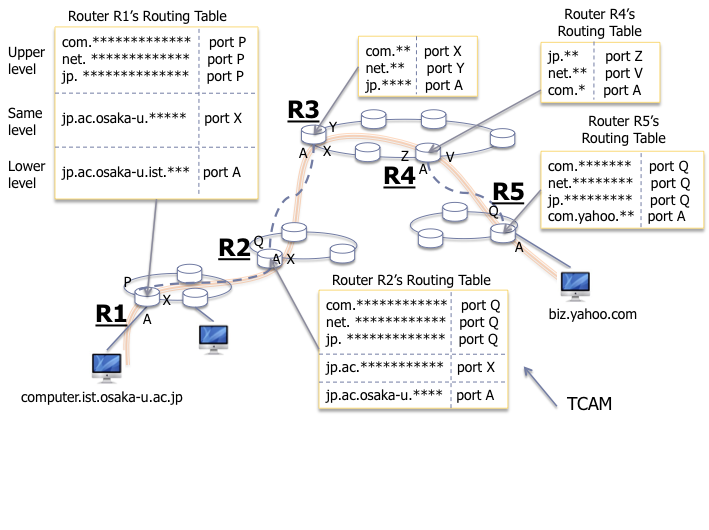
[関連発表論文]
- Haesung Hwang, Shingo Ata and Masayuki Murata, “Resource name-based routing in the network layer,” to appear in Journal of Network and Systems Management, 2013.
5.2.2 IPv6 ネットワークの活用により早期展開を実現するコンテンツセントリックネットワークに関する研究(日本電気株式会社との共同研究)
コンテンツセントリックネットワークは従来の IP ネットワークの通信パラダイムとは抜本的に異なるため,クリーンスレートからの設計が一般的に考えられているが,クリーンスレートからの実現には,アーキテクチャの設計,リファレンスモデルの作成および実験検証,実用化に向けた最適化のプロセスを経る必要があり,実現には相当の時間が要することは想像に難くない.本研究ではコンテンツセントリックネットワークを早期かつ速やかに展開することを目指し,IPv6アドレスを用いた CCN の実現に向けた研究開発を行う.それによって,IPv6 ネットワークアーキテクチャの持つ広いアドレス空間,および既存の IP ネットワークのもつ高い性能,柔軟性,耐障害性を最大限に活用することで,すべてを再構築することなく CCN が実現できることを明らかにする.IPv6 技術を用いた CCN を実現することにより,IPv6 に新たな付加価値を提供する.その結果,エンドユーザの移行を促進させ,IPv6 の持つ広大なアドレス空間を活かしたセキュアなサービスを実現可能であると考える.本研究では,IPv6 ネットワークによる CCN の実現のための通信アーキテクチャ,および必要となる要素技術の設計開発を行った.実験ネットワークでの検証により,特にエンドユーザのアプリケーションを修正することなく容易にコンテンツセントリックネットワークが実現できることを明らかにした.
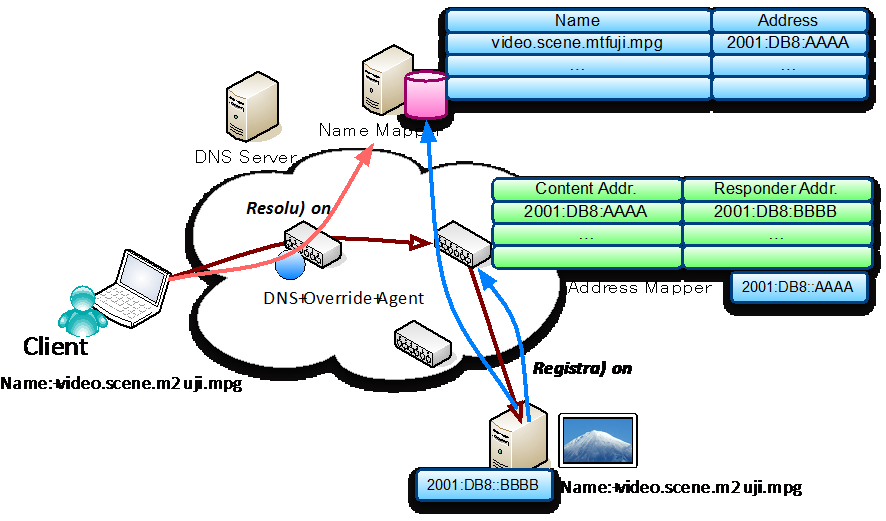
[関連発表論文]
- Shingo Ata, Hiroshi Kitamura, and Masayuki Murata, “Towards early deployable Content-Centric Networking enhanced by using IPv6,” to be presented at IEEE/IFIP International Workshop on Management of the Future Internet (ManFI 2013), May 2013.
- 阿多 信吾, 北村 浩, 村田 正幸, “IPv6 ネットワークとセッション変動型アドレスの併用による安全なコンテンツ指向ネットワークの実現,” 電子情報通信学会技術研究報告(IN2012-185)(発表予定), March 2013.
5.2.3 SDN/OpenFlowによるコンテンツセントリックネットワークの実現手法に関する研究(日本電気株式会社との共同研究)
SDN (Software Defined Network) および OpenFlow は,高いプログラマブル性によってネットワークを柔軟に構成,管理できる技術として近年注目されている.OpenFlow の持つ柔軟性の高いパケット処理記述は,よりインテリジェントなパケット処理が必要となる CCN においても有効であると期待されることから,CCN を OpenFlow により実現する研究が行われている.しかしながら,これまでの研究では概念的な提案にとどまっており,具体的な構成方法やその性能に関する検討はなされていない.本研究では,フォワーディングおよび端末間通信の実現の観点から,OpenFlow による CCN の詳細な設計と実装を行った.具体的には,コンテンツ識別子に対して階層構造を持ったハッシュ値にマッピングし,最長プレフィックスマッチングを用いることで,階層型の名前構造を持つ CCN の実現を行った.
[関連発表論文]
- Atsushi Ooka, Shingo Ata, Toshio Koide, Hideyuki Shimonishi and Masayuki Murata, “OpenFlow-based Content-Centric Networking architecture and router implementation,” submitted for pub-lication.
5.2.4 コンテンツセントリックネットワークにおけるキャッシュ利用の効率化に関する研究
CCN を用いた利点として,コンテンツをルータノードでキャッシュすることによるネットワークの利用効率の向上,応答時間の短縮などが挙げられる.しかし,コンテンツおよびノードの人気集中によるキャッシュ利用の非効率性が指摘されている.具体的には,人気のあるノードにアクセスが集中し,その周辺経路のキャッシュが頻繁に更新されることで,キャッシュの利用効率が低下することが考えられる.特に CCN では,今後ますます大容量化する多数のコンテンツを有効にキャッシュするためには,利用効率の高いコンテンツキャッシュ法,およびそれを実現するコンテンツ分散配置手法が必要不可欠であると考えられる.
本研究では,キャッシュの利用効率を向上させるため,あらかじめ人気コンテンツを特定ノードに集中させるのを防ぎ,広域に分散させるコンテンツ配置手法を提案する.具体的には,下位ルーティングプロトコルのアドレッシングアーキテクチャを活用しコンテンツ名に基づいて生成されたランダムエンコードアドレスをコンテンツに与え,ランダムエンコードアドレスが示すノードにコンテンツを初期配置する.そして,コンテンツへのルーティングにもランダムエンコードアドレスを用いて行うことにより,コンテンツの分散化を実現する.そしてルータノードでは確率的にキャッシングを行うことにより単純かつ効果的なキャッシュ配置を実現するCCN アーキテクチャを提案する.以上の提案手法についてシミュレーションによる性能評価を行い,ランダムエンコードアドレスと確率的キャッシングの組み合わせがコンテンツの分散配置に有効に機能し,ノード数 184 の Level3 トポロジーにおいて,キャッシュヒット率が 15% 向上することを示した.
[関連発表論文]
- 北出雄麻, “CCN におけるエンコードアドレスによるコンテンツ分散配置手法とその評価,” 大阪大学基礎工学部情報科学科特別研究報告, February 2013.
5.3 IPv6の利用促進に向けた研究(日本電気株式会社との共同研究)
IPv4 アドレスの新規割り当てが2012年に終了し,アドレス枯渇問題がいよいよ現実的となった現在,IPv6 ネットワークへの速やかな移行が求められている.しかしながら IPv6 移行に際しては,従来の IPv4 からの変化に伴う課題について検討していく必要がある.その一つがアドレス長の変化による影響である.IPv6アドレスは128bitもあり長いために人間がその値を記憶するのは困難である.それに加え自動で生成設定されるアドレスは人間には規則性のない数字の羅列と感じられ,数字表記のIPv6アドレス情報は,IPv4アドレスとは異なり,実質的にほとんど覚えることができない.アプリケーションの引数として人がアドレスをタイプするのも大変煩雑である.別の視点として,IPv6アドレス情報が人に通信状態を伝えるために提示された場合,そのアドレスが実際にどのノードに設定されたものかを人間が理解できないとその情報は役に立たない.覚えることができない あるいは一目で(他のアドレスと同一かどうかなど)見分けることができない 数字表記のIPv6アドレス情報は,結果として実質的にほとんど意味のない情報になってしまっている.また,IPv6では1ノード(インターフェース)に対して複数のアドレス(リンクローカルアドレスに加えグローバルアドレス)を設定するのが一般的であり,アドレスが実際にどのノードに設定されているものかを人が識別するのを一層難しくしている.
本研究では上記の問題を統合的に解決すべく設計実装したAuto Nameと呼ぶ機能について提案を行っている.全てのIPv6 アドレスに対応するAuto Nameと呼ぶネームを自動で生成登録し,これを利用することで上記の問題を解決している.同じノード(インターフェース)に設定された複数のアドレスに対しては同じAuto Name Prefixを用いることでグループ化し,アドレスが実際にどのノードに設定されているのかを分かり易く示すことにも貢献している.Auto Nameは固定長文字列であるため,アドレス表示の際に桁が揃い見やすくなるなどの副次的な効果もある.本研究では Auto Name 機能の設計,実装および評価により,よりエンドユーザが簡便に IPv6 アドレスを取り扱うことができることを明らかにした.
[関連発表論文]
- 北村 浩, 阿多 信吾, 村田 正幸, “DNS を応用的に用いることで利用が容易で通信ノードの情報を簡単確実に提供できるシステム,” 電子情報通信学会技術研究報告(IN2012-181)(発表予定) , March 2013.