8. 脳や生体の環境適応性・進化適応性に着想を得た情報ネットワークアーキテクチャに関する研究
8.1. 自己組織化制御技術の確立に関する研究
8.1.1. 自己組織的な役割分担機構のネットワーク制御応用のための特性解析
2.1.3節再掲
8.1.2. 化学反応式を用いた空間協調モデルに基づくサービス空間構築手法
3.2.2節再掲
8.1.3. トラヒック統計情報を用いたフロー分類への群知能に基づくクラスタリング手法の適用)
5.2.2節再掲
8.1.4. フォトニックインターネットにおける論理トポロジー制御手法(NTTネットワークサービスシステム研究所との共同研究)
7.1.1節再掲
8.1.5. 生命システムに学ぶ論理トポロジー制御手法(脳情報通信融合研究センター(CiNet)との共同研究)
7.1.2節再掲
8.2. 複雑適応系としてのネットワークにおける制御技術の確立に関する研究
8.2.1. 堅牢性向上のためのインターネットトポロジー設計手法
インターネットの規模が大きくなるとともに、インターネットの堅牢性が重要視されつつある。堅牢性とは、ネットワーク機器やネットワーク機能の一部に障害が発生したとしても、ネットワークとして機能を果たす性質である。これまでにもネットワークの高信頼化へ向けたネットワークトポロジーの構築手法や、障害発生時に短時間で復旧可能な経路制御手法など、様々な研究が行われてきたが、その多くは単一のネットワークを対象としたものであった。しかしインターネットは複数のAS間が接続することにより形成されており、個々のAS が管理するネットワークは小さな局所ネットワークが相互に接続することによって構成されている。そのため、単一のネットワークの信頼性向上だけではなく、ネットワーク全体の堅牢性向上を目指す必要がある。本研究では、ネットワーク全体の堅牢性向上のために、複数のネットワーク間をどのように接続すればよいかを明らかにしている。まず、ネットワーク内のノードに関する固有ベクトル中心性指標を用いて、 Central と Peripheral に分類し、 Central と Peripheral ノードを様々に組合せて異なる構造を持つネットワークを構築し、障害に対する信頼性を評価した。評価の結果、ネットワークの地域トラヒックを集約する役割のノードを接続に用いることで、障害に対する信頼性が向上することが明らかになった。
[関連発表論文]
- Yuka Takeshita, “Strategy of making reliable and efficient interdependent networks,” Master's thesis, Graduate School of Information Science and Technology, Osaka Uni-versity, February 2015.
8.2.2. 自己組織型ネットワーク制御の収束性・適応性・安定性向上
2.1.1節再掲
8.2.3. 自由エネルギーに基づくネットワーク設計
2.1.2節再掲
8.3. 脳ネットワークの構造分析と情報ネットワーク設計・制御手法への応用に関する研究
8.3.1. 脳機能ネットワークの接続構造の分析とインターネットの高機能・高品質化への応用
インターネットは世界最大規模の人工ネットワークであり、大規模複雑化するインターネットをより高品質なものにすることが望まれている。高品質化への手がかりは、多彩な機能を高度なレベルで発揮しているヒトの脳機能ネットワークに見出すことができる。ヒトの脳は非常に複雑でありながら少ない消費エネルギーで管理・制御されており、脳が機能を発揮するときの処理は他の生物と比較して高度に最適化されていることが明らかにされてきた。脳機能ネットワークの特性に関する研究として、トポロジー構造をグラフ理論にもとづいて解析することが広く行われており、インターネットには見られない脳機能ネットワークに固有の構造としてボクセルレベルのトポロジーにおいてフラクタル性を有していることが明らかにされている。したがって、脳機能ネットワークのフラクタル性を取り入れることでインターネットの高品質化が期待できる。ただし、そのためには脳機能ネットワークの接続構造とその構造によってもたらされる利点を解明しなければならない。本研究では、脳機能ネットワークの構造的特徴としてフラクタル性に着目し、フラクタル性の要因となる接続構造およびその構造によってもたらされる利点を明らかにする。分析の結果、脳機能ネットワークは機能モジュールの接続性に関するフラクタル性を有しており、比較対象トポロジーと比べて5 倍以上多くの良質な経路を確保していることがわかった。
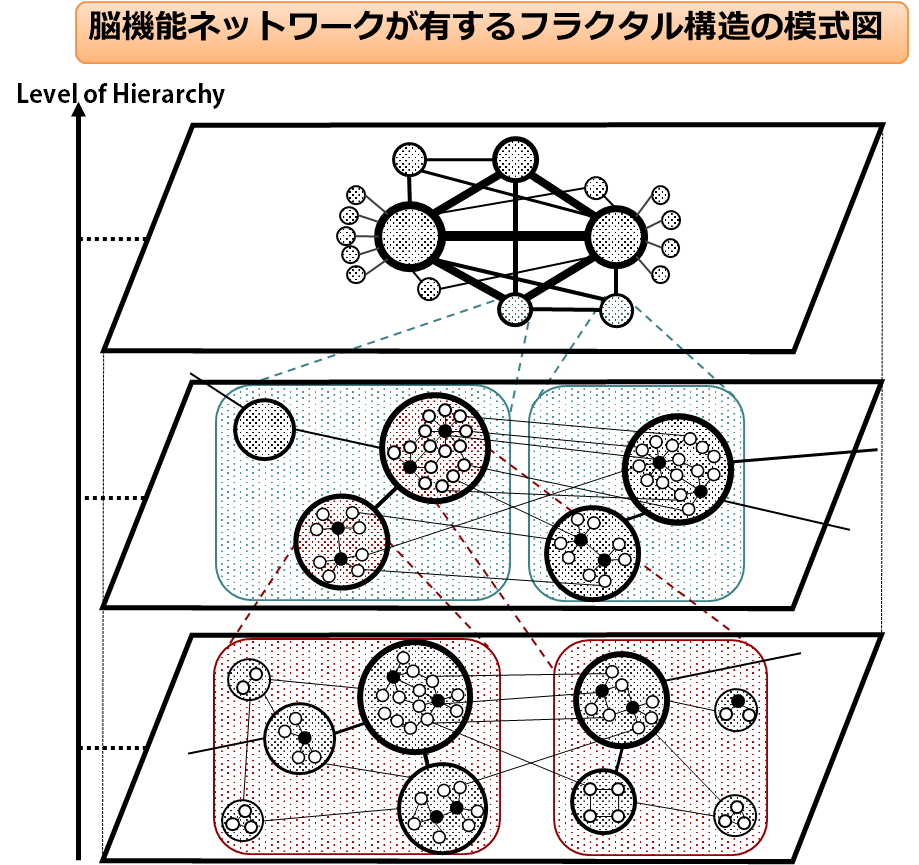
[関連発表論文]
- 四條 能伸, 荒川 伸一, 村田 正幸, “フラクタル性に着目した脳機能ネットワークの接続構造の分析とネットワークの高品質化への応用,” 電子情報通信学会技術研究報告 (IN2014-30), vol. 114, pp. 1-6, July 2014.
- Yoshinobu Shijo, Shin'ichi Arakawa, and Masayuki Murata, “Topological analysis of the brain functional networks,” in Proceedings of the 8th International Conference on Bio-inspired Information and Communications Technologies (formerly BIONETICS), (Boston), December 2014.
8.3.2. 脳ネットワークの構造に着想を得たロバスト性を有するネットワーク構築
2.1.4節再掲
8.4. 生物の進化適応性に基づく持続成長可能な情報ネットワークアーキテクチャに関する研究
8.4.1. インターネットトポロジー成長のモデル化手法
通信需要の増加に伴い、インターネットの規模は拡大し続けている。インターネットでは、AS間の相互接続リンクを通してトラヒックが交換される。しかし、現在のインターネットでは、AS同士の局所的な決定によって相互接続リンクが構築され、インターネットトポロジー全体の構造を考慮したトポロジー成長は行われていない。本研究では、今後の通信需要増加に伴ってインターネットでどのような問題が生じるのかを分析し、また、その問題を回避する方法を検討している。
本研究では、ASレベルトポロジーを、リンクで密に繋がれたAS の集合への分割を繰り返すことで導かれるフロー階層と呼ばれる階層構造を抽出し、その構造の変化を分析している。フロー階層を用いたインターネットトポロジーの経年変化の分析により、現在のリンク構築ポリシーは、一部のリンクにおいてトラヒックをより集中させる傾向にあることがわかった。そこで、このトラヒック集中を抑制するためのインターネットトポロジーの成長方針を示し、この方針に基づくトポロジー成長と過去13年間のインターネットの実際のトポロジー成長と比較した。その結果、トラヒックの集中が半分以下に抑えられることが明らかとなった。しかしながら、トラヒック集中の短絡的な抑制はASの収益を損なう可能性がある。そこで、ASの収益モデルを導入して実際のトポロジー成長を分析した結果、ネットワーク収益の増大に対して、トラヒックの増大の方が大きく、各ASがトラヒックの増大に対して十分なネットワーク収益を獲得できていないことを明らかとなった。そこで本研究では、各ASのリンク構築相手選択ポリシーを提示し、シミュレーション評価によってすべてのASがトラヒックの増大に対してネットワーク収益を持続的に獲得することが可能となることを示している。
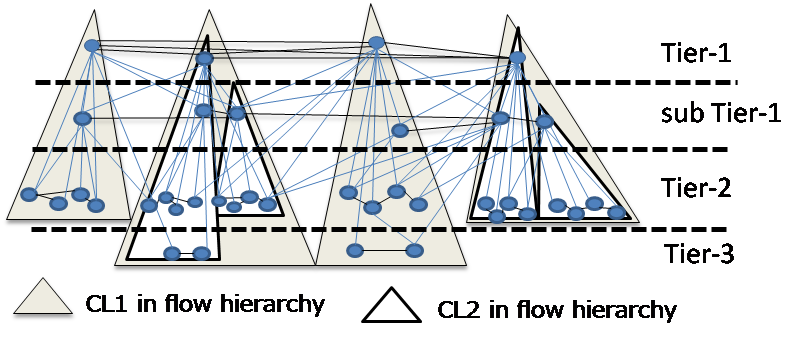
[関連発表論文]
- Yu Nakata, Shin'ichi Arakawa and Masayuki Murata, “A provider and peer selection policy for the future sustainable Internet,” submitted for publication, December 2014.
- Yu Nakata, Shin'ichi Arakawa and Masayuki Murata, “Analyzing the evolution and the future of the Internet topology focusing on flow hierarchy,” submitted for publication, December 2014.
- Yu Nakata, “Topological evolutionary methods for the reliable and sustainable Internet,” PhD thesis, Graduate School of Information Science and Technology, Osaka University, January 2015.
8.4.2. 生物の多様性にもとづく持続成長可能な情報ネットワークの設計手法(KDDI研究所との共同研究)
インターネットの社会インフラ化が進み利用形態が多様化するにつれ、トラヒック需要の変化やネットワーク機器故障に対する適応性や拡張性の高いネットワーク設計が重要になりつつある。しかし、需要の変化や機器故障の事象は予測困難であるため、事前に発生頻度や発生規模を想定して設備設計を行うネットワーク設計手法が広く検討されてきた。ところが、そのようにして設計・構築されるネットワークは、設計時の環境下ではよい性能が得られるものの、環境が大きく変化すると急激に性能が劣化し、大幅な設備増設もしくはネットワークの再設計が必要となる。本研究では、トポロジーの構造に多様性を持たせることで環境変化に対する適応性や拡張性を高め、将来にわたって少ない設備量で環境変化に対応可能なネットワーク設計手法の検討を進めている。
本研究では、トポロジーが有する構造の多様性を測る指標として残存次数の相互情報量に着目し、その有用性を評価する。評価の結果、ルーターレベルトポロジーの残存次数の相互情報量は約1.0となり、トポロジー構造の多様性が低いことがわかった。また、相互情報量が小さいとトポロジー構造が多様となり、相互情報量が大きいとトポロジー構造に規則性が生じることを示した。また、トポロジー構造の多様性を高めるネットワーク設計手法を提案し、FKPモデルに基づいて規模拡張したネットワークと比較評価した。その結果、提案手法に基づいて規模拡張したネットワークは、FKPモデルに基づいて規模拡張したネットワークと比較して、単一ノード故障に対応するために求められる回線設備量を半減することが明らかとなった。
[関連発表論文]
- Lu Chen, Shin'ichi Arakawa, Hideyuki Koto, Nagao Ogino, Hidetoshi Yokota and Ma-sayuki Murata, “A proposal of evolvable network designing approach with topological diversity,” 電子情報通信学会技術研究報告 (PN2014-26), vol. 114, pp. 31-36, November 2014.
- Lu Chen, Shin'ichi Arakawa, Hideyuki Koto, Nagao Ogino, Hidetoshi Yokota and Ma-sayuki Murata, “An evolvable network design approach with topological diversity,” submitted for publication, November 2014.
8.4.3. 生物の進化適応性にもとづく情報ネットワークの構築手法
7.1.3節再掲
8.4.4. Linux カーネルの分析によるインターネットプロトコルスタックの進化過程の評価
環境変動に対して安定して機能する情報ネットワークを構築するにあたっては、ネットワークを構成するプロトコルスタックについても柔軟に再構成可能としておく必要がある。ところがインターネットのプロトコルスタックは、IP(Internet Protocol)を中心とする砂時計型であり、IPおよびTCP (Transmission Control Protocol) / UDP (User Datagram Protocol) が固定的に利用され、機能改変や機能拡張が困難であるという指摘もなされている。最近では、ネットワーク仮想化技術を導入し、ネットワーク機能をコンポーネント化することによって柔軟なサービス提供を可能とするNFV (Network Function Virtualization)やSDN (Software Defined Networking) などの方策も検討され標準化も進められつつある。しかし、NFVやSDNの標準化が進められたとしても、ネットワーク機能をどのようにコンポーネント化し再構成していくかを入念に設計する必要がある。様々な機能が利用される昨今の情報ネットワークでは、すべての機能コンポーネントの組み合わせを網羅的に検証し機能設計することは非現実的であり、コンポーネント組み合わせによる機能進化の適応性を有するプロトコルスタックの構成が必要となると考えられる。このような考えのもと、本研究では、Linuxカーネルにおけるインターネットプロトコルスタックの実装を題材として、プロトコル間及びプロトコル内の機能結合とその進化の様相を分析している。ここでいう様相とは、ネットワーク機能がどのように構成され、また、カーネル開発とともに機能間の接続性の変遷である。Linuxカーネルのバージョン2.6.27から3.6.17におけるネットワーク関連の関数の呼び出し関係に着目して分析した結果、ノード数・リンク数は増加しているものの、次数分布やパス長の分布は変化していないことが明らかとなった。しかし、機能間の独立性を示す尺度であるモジュラリティを評価した結果、機能間の独立性が高くないことがわかった。
[関連発表論文]
- 宮川 裕考, “インターネットプロトコルスタックの進化過程の評価を目的とした Linux カーネルの分析,” 大阪大学基礎工学部情報科学科特別研究報告, February 2015.
8.5. 脳の学習メカニズムの情報通信技術への応用
8.5.1. 深層学習にもとづく動画像シーンの識別
複雑なモデルを表現できる多階層のニューラルネットワークを用いた深層学習と呼ばれる学習手法が注目を集めている。深層学習では、プレトレーニングと呼ばれる教師なし学習で、各ニューロンの接続の重みを決めた上で、教師あり学習を行うことにより、複雑なモデルの学習を行う。
深層学習は、様々な分野で応用されるようになっており、特に画像や動画像の認識への適用は広く研究されている。それらの研究では、画像や動画像ファイル全体に対して識別・分類の処理を行い、正確に画像や動画に写っている事象を識別・分類できることが示されている。しかしながら、これらの従来研究では、動画ファイル全体や、識別したい時点の前後のフレームの情報を用いて動画の識別を行うことを対象としている。それに対して、監視カメラにおける異常検出や長い動画像データからの必要な場面の映像の抽出など、動画像内の各時点のシーンを把握することが重要な動画像識別のアプリケーションも存在する。深層学習を用いて、動画像の各時刻のシーンを識別する方法としては、動画像中の現在からNフレーム前までの連続したフレームを入力とし、識別したいシーンの分類結果を出力とするようなニューラルネットワークを構成することが考えられる。しかしながら、各時点のシーンの識別には、動画像内の動きを認識する必要があり、動きの認識に必要な時間分の全フレームを入力としたニューラルネットワークを構成すると、入力ユニット数が多く複雑なニューラルネットワークが構成される。その結果、識別したいシーンに対する学習データ数が少ない場合は、十分な学習ができずに、正確な識別ができなくなる可能性がある。
そこで、本研究では、現在からNフレーム前までのフレームのうち、サンプリングした少数のフレームを入力としたニューラルネットワークを用いて、動画像のシーンを識別する手法を提案する。提案手法では、現在のシーンの識別に重要であると考えられる、直近のフレームは短い間隔でサンプリングを行い、過去にいくほどサンプリング間隔を広くする。
サンプリングされた入力は、畳み込みニューラルネットワークの入力として用いる。
これにより、シーンを識別するのに必要な少数の入力と出力を対応付けるニューラルネットワークを構成することができ、識別対象のシーンに対する学習データが少ない場合であっても、正確な識別が期待できる。本研究では、映像内の人物の動作をシーンのラベルとしてつけ、シーンの切り替わりのある動画像を用いて、提案手法の評価を行った。評価では、サンプリング間隔を過去に行くほど1ずつ増やしながら、サンプリングした8フレームを入力としたニューラルネットワークを構成した提案手法、連続した直近8フレームを入力として用いた手法、連続した29フレームを入力とした手法を比較した。いずれの入力に対しても、8階層の畳み込みニューラルネットワークを構成し、提案手法と連続した29フレームを入力とした手法では33040個、連続した8フレームを入力とした手法では38440個のサンプルを用いて学習を行った。その結果、連続したフレームを入力として用いた手法では、いずれの時刻においても、60%以上の識別率を達成することはできなかったのに対して、提案手法では、シーン切り替わり後、1秒以降であれば、95%以上の精度でシーンの識別を行うことができることが分かった。
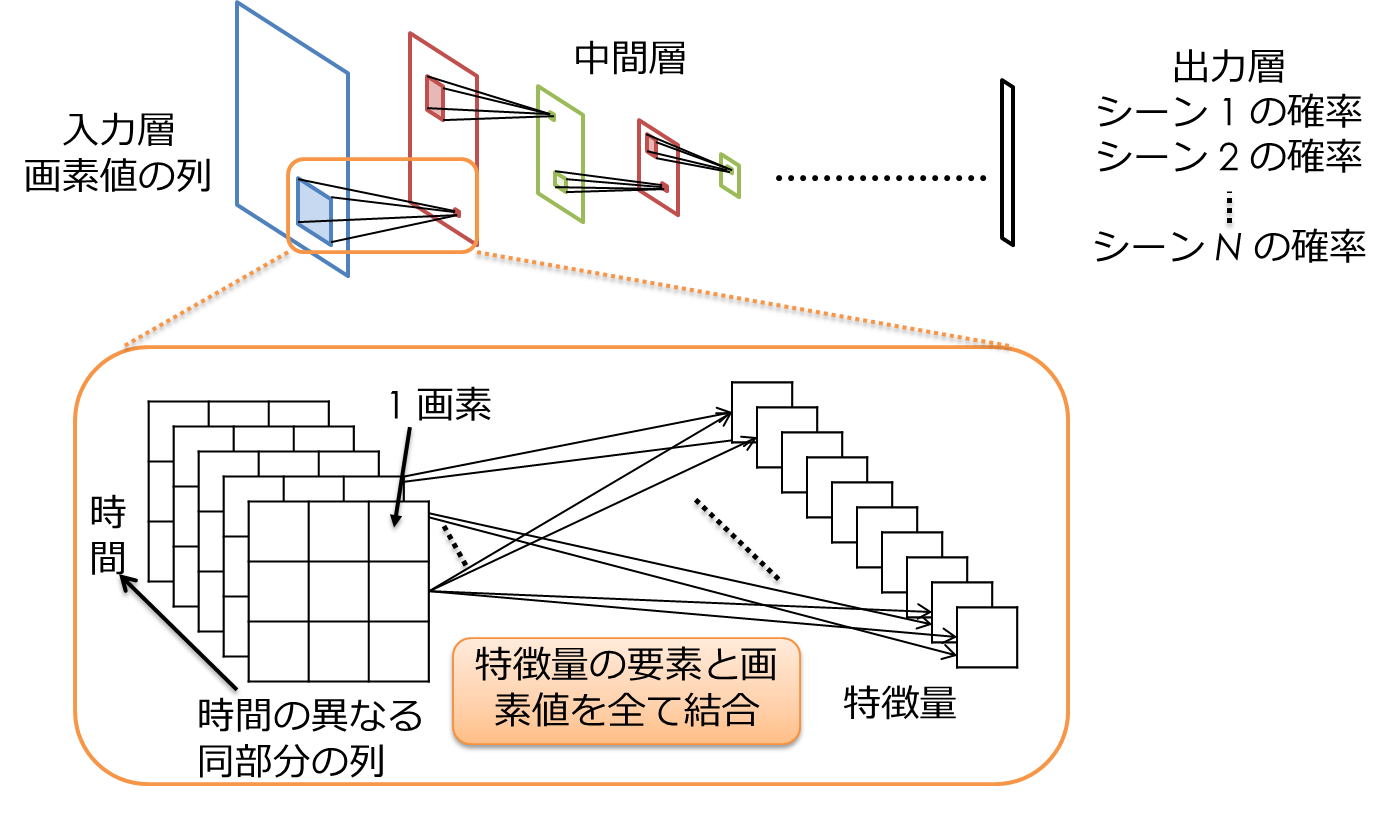
[関連発表論文]
- 山西 宏平, “深層学習に基づく行動に着目したシーン抽出手法,” 大阪大学基礎工学部情報科学科特別研究報告, February 2015.