高速トランスポートアーキテクチャに関する研究
エンドホスト間でデータ系トラヒックを高速に、かつ効率よく転送するための中心技術がトランスポートプロトコルである。特に、近年のネットワークの高速化に伴い、エンドホストにおけるプロトコル処理によるボトルネックも重要な問題となってきている。さらに、ネットワークが拡がりをみせるにつれ、サービスの公平性も重要な課題となってきている。これらの問題は、高速ネットワークにおける輻輳制御と密接な関連を持ち、高速かつ公平なサービスは、単にネットワークの輻輳制御だけでなく、エンドホストの処理能力向上も考慮しつつ、統合化アーキテクチャを構築することによってはじめて実現される。本研究テーマでは、それらの点を考慮した研究に取り組んでいる。また、CDN (Contents Distribution Network)やデータグリッドなどの、IPネットワーク上において特定のサービスを提供するためのオーバーレイネットワークにおけるトランスポートアーキテクチャに関する研究も行っている。
インターネットサーバにおけるスケーラブルな資源割当方式に関する研究
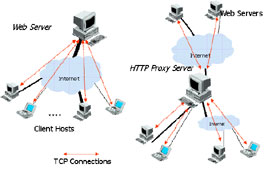
これまでネットワークの高速化に関する研究の多くは、ネットワークにボトルネックがあり、データの送受信を行うエンドホストはボトルネックではないと考えられてきた。そのため、エンドホストの高速化に関する研究はほとんど行われてきていない。しかし、WDM技術等の向上によって現在のネットワーク帯域は増大してきているため、図に示すように多くのTCPコネクションを同時に扱わなければならない非常に繁忙なWebサーバやWebプロキシサーバでは、サーバ資源の管理を行わなければ性能が著しく低下する。この問題を解決するために我々はこれまでに、Webサーバにおける動的な資源管理方式を提案してきた。この方式は、各TCPコネクションのデータ転送速度を向上させることを目的とした送信ソケットバッファの動的割り当て方式、および高速データ転送時のエンドホストにおける通信処理を軽減することを目的としたメモリコピー回避方式からなる。これらの方式をシミュレーションおよび実装実験を用いた評価を行い、提案方式の有効性を確認した。しかし、現在のネットワークにおいてはWebプロキシサーバを介したWebドキュメント転送も多く存在する。また、Webプロキシサーバは一般にISP (インターネットサービスプロバイダ)によって設置されることが多く、Webサーバ間のコネクションとクライアント間のコネクションを収容しなければならないため、Webプロキシサーバにおいて効率的なサーバ資源の管理を行わなければ、Webサーバの性能およびネットワークの帯域が十分にある状況においてWebプロキシサーバがデータ転送のボトルネックとなる状況が発生すると考えられる。
そこで本研究では、Webプロキシサーバのための新しい資源管理方式の提案を行う。本提案方式は、受信ソケットバッファの動的割り当て方式、およびコネクション管理方式からなる。受信ソケットバッファの動的割り当て方式は、受信ソケットバッファの占有率を観測し、その占有率に基づいた受信ソケットバッファの割り当てを行う方式である。コネクション管理方式は、TCPコネクションを保持することによるサーバ資源不足によって新規TCPコネクションを収容することができなくなる問題を回避するために、サーバ資源が不足するとデータ転送を行っていないコネクションを切断し、割り当てた資源を解放する方式である。本論文ではさらに提案方式をシミュレーションおよび実装実験を通して有効性を確認し、その結果提案方式を用いることでWebプロキシサーバの性能を最大50%向上させ、ドキュメント転送時間を約2/3に短縮できることを確認している。
[関連発表論文]
- Go Hasegawa, Tatsuhiko Terai, Takuya Okamoto and Masayuki Murata, "Scalable resource management for high-performance Web servers," submitted to International Journal of Communication Systems, November 2002. [ pdf ]
- Takuya Okamoto, Tatsuhiko Terai, Go Hasegawa and Masayuki Murata, "A resource/connection management scheme for HTTP proxy servers," in Proceedings of IFIP/TC6 Networking 2002, pp. 252-263, May 2002. [ pdf ]
- Takuya Okamoto, Kazuhiro Azuma, Go Hasegawa and Masayuki Murata, "Design, implementation and evaluation of resource management system for Internet servers," submitted to ACM SIGCOMM 2003, January 2003. [ pdf ]
- 岡本卓也, 長谷川剛, 村田正幸, "WebプロキシサーバにおけるTCP受信バッファの動的割り当て手法," 電子情報通信学会技術研究報告 (IN2002-92), pp. 13-18, October 2002. [ pdf ]
- Takuya Okamoto, "Design, implementation and evaluation of resource management system for Internet servers," Master's thesis, Graduate School of Engineering Science, Osaka University, February 2003. [ pdf ]
サービスオーバーレイネットワークにおけるインラインネットワーク計測技術に関する研究
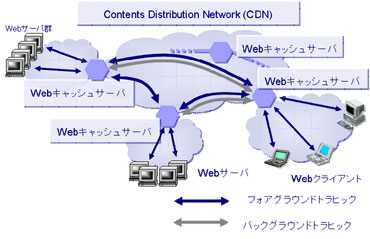
近年のネットワークサービスの多様化に伴い、サービスオリエンテッドなネットワーク(サービスオーバーレイネットワーク)が拡がりつつある。例えば、ピア同士の直接的な通信を実現するP2Pネットワーク、ネットワーク上での分散計算環境を提供するグリッドネットワーク、図に示す、コンテンツ配信を目的としたContents Delivery Network (CDN)、IPネットワーク上に仮想網を構築するIP-VPNなどである。これらのネットワークは、IPネットワークを下位層ネットワークとして、特定のサービスを提供する上位層ネットワークととらえることができる。したがって、これらのネットワークにおいてサービス品質を向上させるためには、下位層ネットワークであるIPネットワークを与条件として、サービス提供のためのコネクション設定要求が発生した時に、利用可能な下位層ネットワーク資源量を適切に把握することが重要である。しかし、既存の利用可能帯域計測方式は、計測に長い時間がかかる、多くの計測用のパケットを用いるため外部トラヒックに与える影響が大きいなどの特徴を持つ。サービスオーバーレイネットワークにおいては、常に最新の利用可能なネットワーク資源量をネットワーク内の他のトラヒックに悪影響を与えることなく取得することが重要であり、そのため既存の方式をそのまま適用することはできない。
そこで本研究では、サービスを提供しているエンドホスト間のTCPコネクションを直接用いて、データ転送中に得られる情報からエンドホスト間の利用可能帯域を随時推測するインラインネットワーク計測方式の提案を行う。この方式により、計測用のパケットをネットワーク内に送出することなく計測を行うことができるため、計測負荷を最小限に抑えることができる。そのために本年度における研究では、まずTCPコネクションによるインライン計測の際に問題となる点を明らかにし、それを解決するために、少ない計測パケット数で計測の初期段階から利用可能帯域の計測結果を導出することのできる、利用可能帯域の計測方式を提案している。シミュレーションによる提案方式の評価の結果、従来方式と比較して、計測のために1度に送信するパケット数を大幅に減少させ、約20個のパケット送信で利用可能帯域を許容範囲内の誤差で算出することができることを明らかにしている。さらに、提案した利用可能帯域の計測方法を、データ転送中のTCPコネクションを用いて行うインラインネットワーク計測方式に関しても検討を行っている。
[関連発表論文]
- Cao Le Thanh Man, Go Hasegawa and Masayuki Murata, "Inline network measurement mechanism for service overlay networks," submitted to IEEE Bandwidth Management Workshop X, (Ontario), January 2003.
- Cao Le Thanh Man, 長谷川剛, 村田正幸, "サービスオーバーレイネットワークのためのインラインネットワーク計測に関する一検討," 電子情報通信学会技術研究報告 (IN03-176), pp. 53-58, January 2003. [ pdf ]
- Cao Le Thanh Man, 長谷川剛, 村田正幸, "アクティブTCPコネクションを用いたインラインネットワーク計測," 電子情報通信学会総合大会 (発表予定), March 2003. [ pdf ]
超高速データ転送を実現するTCPの輻輳制御方式に関する研究
例えば、近年注目されているデータグリッドネットワーク、ストレージエリアネットワーク等においては、エンド端末が1 Gbpsクラスの帯域を持つ高速ネットワークに直接接続され、データの取得・送出、データベースの更新、遠隔バックアップ等において、ギガバイトからテラバイト級のデータを高速に転送することが要求される。このような高速データ転送を行う場合に、現在のインターネットにおいて標準的に用いられているTCP Renoバージョンを用いると、大きなリンク帯域を十分使う程度のスループットを得ることができないという問題が指摘されている。この問題を解決するための一つの方法として、TCP Renoの輻輳制御方式を改変し、高いスループットを得ることができるHighSpeed TCPと呼ばれる方式が提案されているが、その性質はこれまで明らかになっておらず、特に従来のTCP Renoバージョンとの公平性に関しては考慮されていない。
そこで本研究では、HighSpeed TCPコネクションが従来のTCP Renoコネクションと同じリンクを共有する場合の、スループットおよび公平性に関して、数学的解析手法およびコンピュータ上のシミュレーションを用いて考察している。その結果、HighSpeed TCPは従来のTCP Renoに比べて非常に高いスループットを得ることができるが、システム条件によっては大量のパケット廃棄によってスループットが著しく低下し、リンク帯域を十分使う程度のスループットを得ることができない場合があること、また、従来のTCP Renoと同じリンクを共有する場合、TCP Renoを用いたコネクションのスループットを大幅に低下させるため、両者の間の公平性を維持することができない等の問題点を持つことを明らかにしている。さらに本研究では、解析によって明らかになったHighSpeed TCPが持つ問題点を解決し、高いスループットを得るとともに、TCP Renoコネクションとの公平性を改善するTCPの輻輳制御方式の提案を行っている。提案方式の有効性はシミュレーションによって評価を行い、提案方式によって、従来のTCP Renoコネクション公平性を大幅に改善し、HighSpeed TCPに比べて最大で約50%のスループット向上を実現できることを示している。
[関連発表論文]
- Koichi Tokuda, Go Hasegawa and Masayuki Murata, "Performance analysis of HighSpeed TCP and its improvement for high throughput and fairness against TCP Reno connections," submitted to IEEE High Speed Network Workshop 2003 (HSN '03), (San Francisco), March 2003. [ pdf ]
- 徳田航一, 長谷川剛, 村田正幸, "HighSpeed TCP の性能評価とその性能改善方式の提案," 電子情報通信学会情報ネットワーク研究会 (発表予定), March 2003. [ pdf ]
- Koichi Tokuda, "On congestion control mechanism of high-speed TCP," Master's thesis, Graduate School of Engineering Science, Osaka University, February 2003. [ pdf ]
公平性に着目したREDルータの解析的評価と性能改善に関する研究
ボトルネックルータにおけるTCPコネクション間の不公平性を改善するための一つの方法として、RED (Random Early Detection)ルータを用いることが有効であると言われている。そこで本研究では、特にフロー間の公平性に着目し、REDルータの評価を数学的解析手法により行い、その結果、パラメータ設定が適切な場合はREDの公平性はTDに対して優れているが、パラメータ設定が不適切な時にはREDの性能がTDよりも劣化する場合があることを明らかにしている。また、REDのパラメータをルータの輻輳状況に応じて動的に変化させ、ネットワーク状況の変化に対応する動的パラメータ設定方式であるdt-RED (RED with dynamic threshold control) 方式を提案し、性能評価を行っている。さらに、遅延時間やリンク帯域等の環境が同じ場合でも、TCPコネクションが転送するデータサイズの違いによってスループットに不公平性が発生することを指摘し、それを改善する手法として、ルータにおいて転送データサイズを推測し、推測結果に基づいて転送データサイズに応じてREDにおけるパケット廃棄率を変化させるhash-RED方式を提案し、その有効性をシミュレーションによって明らかにしている。
[関連発表論文]
- Go Hasegawa, Kouichi Tokuda and Masayuki Murata, "Analysis and improvement of fairness among many TCP connections sharing Tail-Drop and RED routers," in Proceedings of INET 2002, June 2002. [ pdf ]
- Koichi Tokuda, Go Hasegawa and Masayuki Murata, "Analysis and improvement of fairness among TCP connections transmitting differently sized data," submitted to Journal of High Speed Networks, January 2003. [ pdf ]
- Koichi Tokuda, Go Hasegawa and Masayuki Murata, "Analysis and improvement of the fairness between longlived and short-lived TCP connections," in Proceedings of IEEE Seventh International Workshop on Protocols For High-Speed Networks (PfHSN 2002), (Berlin), pp. 33-40, April 2002. [ pdf ]
- Koichi Tokuda, Go Hasegawa and Masayuki Murata, "TCP throughput analysis with variable packet loss probability for improving fairness among long/short-lived TCP connections," in Proceedings of IEEE CQR 2002, (Okinawa), pp. 145-149, May 2002. [ pdf ]
ネットワークプロセッサを用いたTCPプロキシ機構の実装とその評価に関する研究
近年のインターネットの発達、ユーザの爆発的な増加にともない、インターネット上で提供されるサービスは多様化している。それらの中には、エンド端末間のスープット、データ転送遅延時間、パケット廃棄率などに関して高いネットワーク品質を要求するサービスもあるが、現在のインターネットはベストエフォート型であり、ネットワーク内での通信品質が保証されないため、送受信エンド端末間でTCPやアプリケーションによる通信品質の制御を行っても、アプリケーションの要求を完全に満たすことはできない。この問題を解決するためのIP層における品質制御技術として、IntServやDiffServが挙げられるが、スケーラビリティ、導入コストなどに多くの問題を抱えている。一方、アプリケーション層における品質制御技術に関しても多くの研究が行われ、実ネットワークにおいて運用がされているものもある。しかし、これらの技術はそれぞれのアプリケーションに特化した制御が必要であり、パラメータ設定が難しいという問題がある。
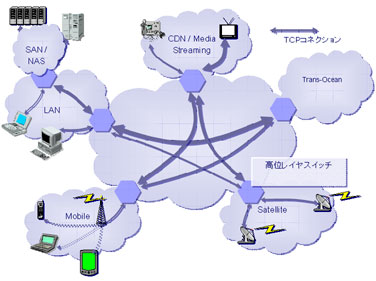
そこで我々の研究グループでは、IPネットワークにおいてはルーティング、パケット到達性などの必要最低限の機能のみを提供し、品質制御はトランスポート層において行う、レイヤ4オーバーレイネットワークに関する研究を行っている。レイヤ4オーバーレイネットワークにおいては、エンド端末間に設定されるTCPコネクションをネットワーク内で図に示すように分割し、それぞれのコネクションにおいてネットワーク環境、要求されるサービスに応じた制御を行うことで、高品質なサービスを提供することができる。本研究においては、レイヤ4オーバーレイネットワークにおいて必要となる基本的な機能である、TCPコネクションをネットワーク内のノードにおいて分割・中継する機能(TCPプロキシ機構)をPCルータおよびネットワークプロセッサを用いて実装し、その性能や処理遅延に関する評価を行っている。評価の結果、TCPコネクションの分割・中継処理においてもっとも大きな性能上のボトルネックになるのはメモリアクセス処理であることを明らかにしている。また、計測結果と解析結果の比較を行うことによって解析結果の妥当性を評価している。さらに、PCルータ上の実装とネットワークプロセッサ上の実装の性能比較を行い、ネットワークプロセッサを用いることの有用性や特徴、および将来の高速ネットワークプロセッサシステムにおけるTCPプロキシ機構の性能などに関する議論を行っている。その結果、今後登場する高速なネットワークプロセッサを用いることによって、ある程度高速なネットワーク上においてもTCPプロキシ機構を提供できることを明らかにしている。
[関連発表論文]
- 松浦陽亮, "TCPプロキシ機構のネットワークプロセッサ上での実装と評価," 大阪大学基礎工学部情報科学科特別研究報告, February 2003. [ pdf ]