3) 次世代高速ネットワークアーキテクチャに関する研究
3.1 高速トランスポートアーキテクチャに関する研究
エンドホスト間でデータを高速に,かつ効率よく転送するための中心技術がトランスポートプロトコルである.特にインターネットで用いられて いるTCPでは,エンドホストがネットワークの輻輳状態を自律的に検知して転送率を決定している.これは,インターネットの基本思想である End-to-end principleの核になっているものであるが,エンドホストの高速化により,その適応性をより高度なものにできる可能性が十分にある. また,ネットワーク内ルータでは,エンドホストの適応性を前提とした制御を考えていく必要があるが,それが実現されれば,自律性,適応性に 富んだ高機能ネットワークの可能性も見えてくる.本研究テーマでは,そのような高速トランスポートプロトコルに関する研究に取り組んでいる. また,CDN (Contents Distribution Network)やデータグリッドなど,IPネットワーク上において特定のサービスを提供するためのオーバーレイ ネットワークにおけるトランスポートアーキテクチャに関する研究にも取り組んでいる.
3.1.1 インラインネットワーク計測技術に関する研究
近年のネットワークサービスの多様化に伴い,サービスオリエンテッドなネットワーク(サービスオーバレイネットワーク)が拡がりつつある.こ れらのネットワークにおいてサービス品質を向上させるためには,下位層ネットワークであるIPネットワークを与条件として,サービス提供のた めのコネクション設定要求が発生した時に,利用可能な下位層ネットワーク資源量を適切に把握することが重要である.
そこで我々の研究グループでは, IP ネットワークのエンドホスト間で利用可能な帯域幅および物理帯域を同時にかつ少ないオーバヘッドで計測 する,インラインネットワーク計測手法を提案している.提案方式は TCP コネクションのデータ転送時に得られる情報に基づいて計測を行なう インラインネットワーク計測と呼ばれる方式であり,新たな計測用のトラヒックをネットワークに導入する必要がなく,かつ計測結果を素早く導 出することが可能となる.物理帯域の計測手法に関しては,同時に計測を行う利用可能帯域値を利用することで,従来手法とはまったく異なるア ルゴリズムを用いて物理帯域の推測を行っている.
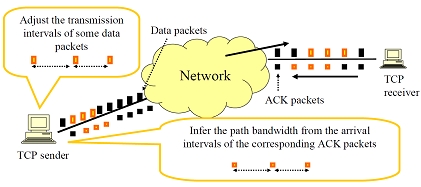
本年度の研究においては,これまでに我々が提案したパケットの送信・受信間隔に基づいた計測手法,および高速ネットワークにおける計測のた めに提案した,パケットバーストの送信・受信間隔に基づいた計測手法をLinuxおよびFreeBSDへ実装し,その有効性を確認した.その結果,低速 および高速インターネット環境において,両手法が期待される性能を発揮することができることを確認した.特に,従来数多く提案のあるパケッ トの送信・受信間隔に基づいた計測手法が,100Mbpsを越える高い帯域を計測できないことを確認し,我々が新たに提案したパケットバーストの 送信・受信間隔に基づく手法が,1Gbpsに達するような広帯域環境においても利用可能帯域を高い精度で計測できることを確認した.
さらに本年度における研究では,オーバーレイネットワークがトラヒックの経路選択を行うために必要となる,経路の帯域情報を知るための,各 オーバーレイノードで分散的に動作する帯域情報収集システムImSystemを提案した.ImSystemは上述のインラインネットワーク計測を利用するこ とにより,帯域計測用のトラヒックを減少させることができる.そのため,帯域情報収集のためにネットワークへ与える負荷が小さいという特長 を持つ.さらに,ImSystem をベースに,計測用のトラヒックが互いに重ならないように計測タイミングを調整するImSystemPlus を提案した.シ ミュレーション評価結果により,提案システムが常に最新の帯域情報を高い精度で把握することが可能であり,かつ,ネットワークへ与える影響 が少ないことを示した.また,オーバレイネットワーク上のトラヒック量が少ない場合においても,提案システムがそれを有効に利用し,計測用 トラヒックを大幅に減らすことができることが明らかとなった.
[関連発表論文]
- Cao Le Thanh Man, Go Hasegawa and Masayuki Murata, "ImTCP: TCP with an inline measurement mecha-nism for available bandwidth," Computer Communications Special Issue: Monitoring and Measurements of IP Networks, vol. 29, pp. 1614-2479, June 2006. [pdf]
- Cao Le Thanh Man, Go Hasegawa and Masayuki Murata, "A simultaneous inline measurement mechanism for capacity and available bandwidth of end-to-end network path," IEICE Transactions on Communications, vol. E89-B, pp. 2469-2479, September 2006. [pdf]
- Tomoaki Tsugawa, Cao Le Thanh Man, Go Hasegawa and Masayuki Murata, "Implementation issues on inline network measurement in high-speed networks," submitted for publication, January 2007.
- Cao Le Thanh Man, Go Hasegawa and Masayuki Murata, "Inline bandwidth measurement techniques for giga-bit networks," submitted for publication, September 2006.
- Cao Le Thanh Man, Go Hasegawa and Masayuki Murata, "ICIM: An inline network measurement mechanism for highspeed networks," in Proceedings of the 4th IEEE/IFIP Workshop on End-to-End Monitoring Techniques and Services (E2EMON 2006), pp. 67-74, April 2006. [pdf] [ppt]
- Tomoaki Tsugawa, Go Hasegawa and Masayuki Murata, "Implementation and evaluation of an inline network measurement algorithm and its application to TCP-based service," in Proceedings of 4th IEEE/IFIP Workshop on End-to-End Monitoring Techniques and Services (E2EMON 2006), (Vancouver, Canada), pp. 35-42, April 2006. [pdf] [ppt]
- Tomoaki Tsugawa, Cao Le Thanh Man, Go Hasegawa and Masayuki Murata, "Implementation issues on inline network measurement in high-speed networks," submitted for publication, January 2007.
- Cao Le Thanh Man, Go Hasegawa and Masayuki Murata, "Inferring available bandwidth of overlay network paths based on inline network measurement," submitted for publication, January 2007.
- 津川知朗,Cao Le Thanh Man,長谷川剛,村田正幸, "高速ネットワークにおけるインラインネット ワーク計測手法の実装に関する検討および性能評価," 電子情報通信学会技術研究報告(IN2006-47), pp. 73-78, July 2006. [pdf] [ppt]
- Cao Le Thanh Man, Go Hasegawa and Masayuki Murata, "Inferring bandwidth of overlay network paths using inline network measurement," 電子情報通信学会技術研究報告, March 2007.
- Cao Le Thanh Man, "Inline Network Measurement: TCP Built-in Techniques for Inferring End-to-end Band-width," PhD thesis, Graduate School of Information Science and Technology Osaka University, January 2007. [pdf] [ppt]
3.1.2 インラインネットワーク計測技術を利用した新たなTCPサービスに 関する研究(NEC社との共同研究)
前項のインラインネットワーク計測技術を用いることにより,TCPコネクションが転送中のデータ・ACKパケット を利用して,ネットワークパスの帯域に関する情報を獲得することができる.この情報を用いることで,従来実 現できなかった,あるいは,従来アプリケーション層で実現する必要のあったさまざまなネットワークサービス を,トランスポート層,つまりTCPの制御によって実現することができると考えられる.本年度における研究で は,一定のスループットを確保したデータ転送を実現するTCPの輻輳制御手法に関する検討を行った.
インターネットの発展によりサービスが多様化し,リアルタイム配信型アプリケーションなど,通信品質の確保 を必要とするアプリケーションが注目されている.これまで,IP 層やアプリケーション層において高い通信品 質を提供する手法が提案されているが,ネットワーク規模に対するスケーラビリティや導入コストなどの問題か ら実現が困難とされている.そこで本研究では,トランスポート層において高い通信品質を実現する一方式とし て,TCP コネクションを用いてある一定のスループットを上位アプリケーションに提供する,TCP の輻輳制御方 式を提案した.提案手法は,送信側TCP の輻輳ウィンドウサイズの増加方法を変更することで,データ送信レー トを制御する.
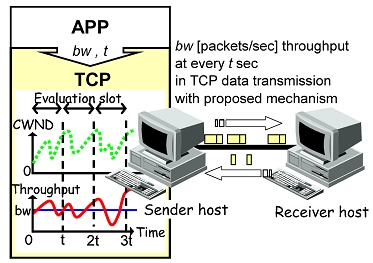
提案手法の評価はシミュレーションによって行い,その結果,背景トラヒック量が多く,利用可能帯域がほとん ど存在しない環境においても,物理帯域の約10-20%のスループットを高い確率で獲得できることを示した.さら に,提案方式をLinux上へ実装し,研究室内の小規模実験ネットワーク,および大阪-東京間の公衆インターネッ ト環境において実験を行った.その結果,提案方式がコンピュータシミュレーションとほぼ同程度の性能を発揮 できることを確認した.
[関連発表論文]
- Tomoaki Tsugawa, Go Hasegawa and Masayuki Murata, "Background TCP data transfer with inline network measurement," IEICE Transactions on Communications, vol. E89-B, pp. 2152-2160, August 2006. [pdf]
- Kana Yamanegi, Go Hasegawa and Masayuki Murata, "Congestion control mechanism of TCP for achieving predictable throughput," in Proceedings of ATNAC 2006, pp. 117-121, December 2006. [pdf] [ppt]
- 山根木果奈, 長谷川剛, 村田正幸, "インラインネットワーク計測に基づくTCP スループットの保証手法," 電子情報通信学会技術研究報告(IN2006-50), pp. 7-12, September 2006. [pdf] [ppt]
- 山根木果奈, 長谷川剛, 村田正幸, "スループット保証を実現するTCP の輻輳制御方式の実装評価," 電子情報通信学会技術研究報告, March 2007. [pdf]
- Kana Yamanegi, "TCP congestion control mechanisms for achieving predictable throughput," Master's thesis, Graduate School of Information Science and Technology, Osaka University, February 2007. [pdf] [ppt]
3.1.3 エッジルータにおける改造TCPコネクションの検出・制御技術に関 する研究
現在のインターネットには,悪意あるユーザによって改造されたTCP が存在する.これは,カーネル内のソース コードやパラメータを少し変えるだけでTCPを改造できることに起因する.例えば,輻輳ウィンドウサイズの増 減のレートを変更するには,カーネル内のソースコードのうち,輻輳ウィンドウサイズの増加幅と減少幅を決定 しているパラメータを変更するだけでよく,わずか数行の改変で改造が可能である.この様にして改造された TCP を,ここではtampered-TCP と呼ぶ.
本研究では,tampered-TCPがネットワークに与える影響を評価した.具体的には,tampered-TCP の中でもウィ ンドウサイズの上げ幅と下げ幅を変更したものを対象とし,数学的解析手法を用いて,TCP Reno コネクション とtampered-TCP コネクションが共存する環境における,tampered-TCP コネクションの平均スループットを導出 した.さらに,シミュレーション評価によって数学的解析手法の妥当性を検証し,(1) 上げ幅が3 以上の場合, 再送タイムアウトが増加することによってスループットが低下すること,(2) 下げ幅を小さくすることでスルー プットが増大すること,(3) 下げ幅を小さくすることの効果より,上げ幅の増加によるスループットの低下の影 響の方が強いこと,などを明らかにした.また,これらの結果を通じて,tampered-TCP の有効範囲がごく狭い 領域に限られることを示した.
さらに,エッジルータにおいてtampered-TCP コネクションを検出・制御することによって,通常のTCP コネク ションを保護し,TCP コネクション間の公平性を実現する手法を提案した.提案手法は,エッジルータにおいて TCP パケットを観測することにより,TCP コネクションのウィンドウサイズ,あるいはスループットを推測する. さらに,その値をもとにTCP コネクションのタンパリング性を判断し,必要に応じてパケットを意図的に廃棄す る.シミュレーション評価により検証した結果,提案手法によってtampered-TCP コネクションを高い確率で検 出し,TCP Reno コネクションとのスループット比をほぼ1 に保つことができることを明らかにした.

[関連発表論文]
- Junichi Maruyama, Go Hasegawa, and Masayuki Murata, "Is tampered-TCP really effective for getting high throughput in the Internet?," in Proceedings of ATNAC 2006, pp. 167-171, December 2006. [pdf] [ppt]
- 丸山純一, 長谷川剛, 村田正幸, "改造TCP がネットワークに与える影響に関する一検討," 電子情報通信 学会技術研究報告(IN2006-40), vol. 106, no. 151, July 2006. (情報ネットワーク研究賞) [pdf] [ppt]
- 丸山純一, 長谷川剛, 村田正幸, "エッジルータにおける改造TCP の検出・制御手法の提案," 電子情報通 信学会技術研究報告, March 2007. [pdf]
- Junichi Maruyama, "Ill-effects of tampered-TCP flows and protection mechanisms for well-behaved TCP flows," Master's thesis, Graduate School of Information Science and Technology, Osaka-University, February 2006. [pdf] [ppt]
3.1.4 生物の増殖モデルに基づくTCPの輻輳制御方式
帯域や遅延が大きいネットワークにおいてTCP Reno を用いた場合においてスループットが低下することが問題 点として挙げられる.この問題は,ウィンドウサイズの増加量を決定するパラメータが小さく(1 ラウンドトリッ プ時間(RTT) あたり1 パケット) ,ウィンドウサイズの減少量を決定するパラメータが大きい(パケット廃棄発 生時に半減させる) ことに起因している.この問題に対する解決法は数多く提案されているが,それらの多くは TCP Reno のウィンドウサイズ制御の基本的機構であるAIMD 方式を引き継いでおり,その増減の量を決定するパ ラメータをネットワーク環境に応じて静的あるいは動的に調節することでスループットの改善を行っている.
しかし,それらの多くは特に帯域や遅延が大きいネットワーク環境を想定した修正であるため,他の環境におい て適用された場合にも問題点を持たないかどうかは不明であり,本質的な解決を行っているとはいえない.これ は,TCP Reno は送受信ホスト間のパスのRTT を計測しているが,利用可能帯域を知るための効率的な方法を持 たないためである.すなわち,TCP が何らかの手法を用いて,送受信ホスト間のパスの帯域に関する情報をすば やく,高い精度で取得することができれば,ウィンドウサイズの制御にAIMD 方式を用いる必要はなく,より効 率の良い輻輳制御方式を考えることが可能となる.
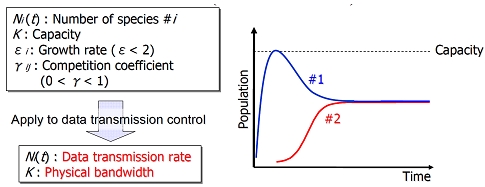
これらの問題に対してわれわれは,インライン計測技術を用いて帯域に関する情報を取得し,その情報を用いて ウィンドウサイズ制御を行うことによって,従来のTCP Reno における問題を本質的に改善するための新たなTCP の輻輳制御方式を提案している.ウィンドウサイズ制御のアルゴリズムは,帯域に関する情報を用いることによっ てウィンドウサイズを適切な値にすばやく調節すること,および他のコネクションが競合する際に公平に帯域を 分配できることを目的として設計する.そのために,数理生態学において生物の個体数の変化を表すモデルとし て有名なロジスティック増殖モデル,およびロトカ・ヴォルテラ競争モデルを適用する.これらのモデルをTCP のウィンドウサイズ制御へ適用するために,生物の個体数をデータ転送速度に,個体数の収束値である環境容量 を物理帯域に,および種間の競争を同一リンク上の複数コネクションの競合にそれぞれ変換する.本研究では, 提案方式の特性を数学的解析によって明らかにし,提案方式が持つパラメータ設定方法に関する議論を行った. また,前述の高速ネットワークにおけるインラインネットワーク計測手法を用いて,ネットワークパスの物理帯 域および利用可能帯域を取得することによって,提案している輻輳制御方式が,将来の超高速ネットワーク環境 においても十分な性能を発揮することができることを明らかにした.
さらに,提案手法をLinuxへ実装し,研究室内の小規模実験ネットワーク,また,大阪-東京間および大阪-米国 カリフォルニア間の公衆インターネット環境を用いて,データ転送実験を行った.その結果,インライン計測に よって正確な利用可能帯域の値が得られる場合には,低速・低遅延環境においても十分な性能を発揮できること, また,高速・高遅延ネットワーク環境においては,計測精度が低下したとしても,従来手法に比べて最大で100% のスループット向上を達成できることがわかった.
[関連発表論文]
- Go Hasegawa and Masayuki Murata, "Self-adaptive and scalable TCP congestion control based on inline net-work measurement," submitted for publication, December 2006.
- Go Hasegawa and Masayuki Murata, "TCP symbiosis: congestion control mechanisms of TCP based on Lotka-Volterra competition model," in Proceedings of Workshop on Interdisciplinary Systems Approach in Per-formance Evaluation and Design of Computer & Communications Systems (Inter-Perf 2006), (Pisa, Italy), Oc-tober 14, 2006. [pdf] [ppt]
- 児玉瑞穂, "インライン計測に基づいたTCP 輻輳制御方式のネットワークにおける性能評価," 大阪大学基 礎工学部情報科学科特別研究報告, February 2007 [pdf] [ppt]
3.1.5 TCPトラヒックを考慮した大規模IPネットワークの性能評価に関す る研究
インターネットユーザの増大,アプリケーションの多様化にともない,インターネットは加速度的に大規模・複 雑化している.それにともない,そのような大規模ネットワークの設計手法や,性能解析手法に対する要求が高 まっている.しかし,インターネットトラヒックの大部分を占めるTCPの挙動を考慮した大規模ネットワークの 性能解析・評価手法は,十分に整備されていないのが現状である.
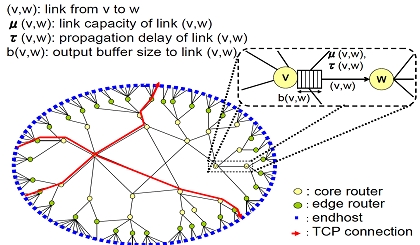
そこで本研究においては,TCP の輻輳制御を考慮した,大規模ネットワークの解析手法を提案した.本解析では, エンドホストで動作するTCP およびネットワークリンクを,それぞれ独立のシステムとしてモデル化し,これら を相互接続することで,大規模ネットワークをモデル化している.各リンクにおけるリンク利用率およびパケッ ト棄却率,そしてTCP コネクションのスループットを導出し,ネットワークの輻輳個所およびその輻輳の度合を 求める.我々の解析手法を用いることによって,例えば,100 /1,000 /100,000 を越えるルータ/ エンドホスト / リンク,そして,100,000 本を越えるTCP コネクションが存在するネットワークのエンド間のスループット, リンク利用率等を短時間で評価できる.また,評価に必要な計算時間は,ns-2 とは異なり,ネットワークの帯 域および伝播遅延に依存しない.本研究では,解析結果をシミュレーション結果と比較することにより,解析の 妥当性を示した.さらに,我々の解析手法が,大規模ネットワークにおけるTCP コネクションの振舞いを適切に 捉えていることを明らかにした.
さらに,提案した解析手法を用いて,コアネットワークおよびエッジネットワークを含んだ大規模なネットワー クにおいて,コアルータのバッファサイズを小さくすることの妥当性を検証した.具体的には,解析手法を Abilene-inspired ネットワークに適用することにより,コアルータのバッファサイズを小さくすることが,ネッ トワークおよびTCP コネクションの性能にあたえる影響を調査した.その結果,エッジネットワークのリンク帯 域が大きくなったとき,コアルータのバッファサイズを小さくすることは,コアルータを通過するTCP コネクショ ンと通過しないTCP コネクション間に,大きな不公平性を引き起こすことが明らかとなった.
[関連発表論文]
- Hiroyuki Hisamatsu, Go Hasegawa and Masayuki Murata, "Performance analysis of large-scale IP networks considering TCP traffic," submitted for publication, December 2006.
- Hiroyuki Hisamatsu, Go Hasegawa and Masayuki Murata, "Sizing router buffers for large-scale TCP/IP net-works," to be presented at The 2007 International Symposium on Frontiers in Networking with Applications (FINA 2007), May 2007.
- 久松潤之, 長谷川剛, 村田正幸, "TCP トラヒックを考慮した大規模ネットワーク解析手法の提案," 電子 情報通信学会技術研究報告(CQ2006-7), pp. 31-36, April 2006.
- 久松潤之, 長谷川剛, 村田正幸, "大規模ネットワークにおけるTCP トラヒックを考慮したルータのバッファ サイズの検討," 電子情報通信学会技術研究報告(IN2006-130), pp. 97-102, December 2006.
3.1.6 インターネットルータのバッファサイズに関する研究
現在,インターネットルータのバッファサイズの決定には帯域遅延積を指標とする方法(以下normal 指標と称 する)が広く利用されている.これに対し,TCP を用いた通信が多数存在するという条件の下であれば,ネット ワークリンクの利用率を維持するためには帯域遅延積をフロー数の平方根で除算しただけのサイズで十分である という方法(以下sqrtN 指標と称する)が提唱されている.また,TCP コネクションのデータパケット転送にお けるバースト性を緩和する手法であるpaced TCP を用いることによって,さらに小さい数十パケットのバッファ サイズで十分であるという主張も提起されている.しかし,これら主張はボトルネックリンクの利用率以外の視 点からの十分な評価が行われていない.
そこで本研究では,ns-2 を用いたシミュレーションにより,paced TCP がルータのバッファサイズの設定に与 える影響を,さまざまな視点から考察した.その結果,paced TCP の導入により,ほとんどの場合でパケット廃 棄率が小さくなるものの,パケット廃棄率がnon-paced TCP とほとんど差がない場合は,データ転送遅延時間に 悪影響を及ぼし,リンク利用率も高く維持できないことが明らかとなった.また,paced TCP とnon-paced TCP が混在した環境においては,normal 指標ではpaced TCP フローが増加するにつれ,paced TCP のスループット が大きくなるが,sqrtN 指標の場合はpaced TCP のフロー数に関係なくnon-paced TCP のスループットのほうが 高く,paced TCP を普及させるにはsqrtN 指標では不適当であり,バッファサイズを大きくする必要があること が明らかとなった.
[関連発表論文]
- 多田健太郎, 長谷川剛, 村田正幸, "Paced TCP がルータのバッファサイズ設定に与える影響," 電子情報 通信学会技術研究報告, March 2007. [pdf] [ppt]
- 多田健太郎, "TCP のバースト性およびその緩和手法がルータのバッファサイズ決定に与える影響," 大阪 大学基礎工学部情報科学科特別研究報告, February 2007 [pdf] [ppt]
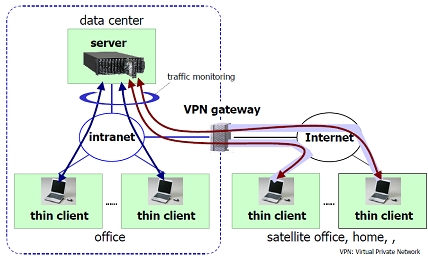
3.1.7 トランスポートプロトコルの改良によるシンクライアントシステム の性能向上に関する研究
シンクライアントシステムとは,クライアントからキーボード・マウスイベントを送信し,サーバから処理結果 の画面情報を受信するシステムを指し,そのトラヒックは,文字情報に相当するインタラクティブな特性のトラ ヒックと,ウィンドウなどの画面情報に相当するバルク転送的な特性のトラヒックに大別できる.本研究におい ては,前者に対してパケットロスへの耐性向上を課題として,データパケットの複製同時送信を提案し,後者に 対しては,スループットの向上を課題として,TCP のスロースタート再スタート (SSR) の影響を評価するとと もに,データセグメントの再構成手法に関する検討を行った.
実トラヒックを利用したシミュレーションにより評価を行った結果,インタラクティブなトラヒックにおいて, ランダムなパケットロスに対しては効果を得られることがわかった.また,バルク転送的なトラヒックのバース ト性が,SSR 設定オフにより増大し,セグメント再構成により緩和されることを明らかにした.
[関連発表論文]
- 小川祐紀雄, 長谷川剛, 村田正幸, "シンクライアントトラヒックの性能向上手法の検討," 電子情報通信 学会 情報ネットワーク研究会, March 2007.
3.1.8 TCPオーバレイネットワークに関する研究(NEC社との共同研究)
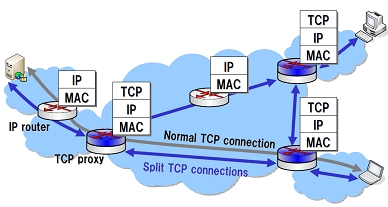
我々の研究グループでは,IP層やアプリケーション層において品質制御を行うのではなく,IP層においては従来 のルーティングなど必要最低限の機能のみを提供し,品質制御をトランスポート層において行うTCPオーバレイ ネットワークに関する研究を行っている.TCPオーバレイネットワークにおいては,通常エンドホスト間に設定 されるTCPコネクションをネットワーク内のノード(TCPプロキシ) で終端し,分割されたコネクションごとにパ ケットを中継しながら転送を行う.これにより,TCPコネクションのフィードバックループを小さくすることが 可能になるため,スループットの向上を期待することができる.また,TCPオーバレイネットワークを構築する ことによって,ネットワーク環境の違いを吸収することが可能になるため,要求されるサービス品質に応じた制 御を行うことが可能になる.
そこで本研究では,TCP オーバレイネットワークにおける基本技術であるコネクション分割に着目し,コネクショ ン分割を行うことによりエンドホスト間のデータ転送速度が向上すること,および,プロキシノードにおけるパ ケット処理のオーバヘッドが原因になり,期待するほどのスループットが得られないことを明らかにした.また, これらの影響を考慮したエンドホスト間のスループット解析を示し,その妥当性をシミュレーションとの比較に より検証した.その結果,スループット劣化はTCPプロキシの前後のコネクションが通過するネットワーク環境 に差が少ない場合に大きくなり,最大で約60%性能が低下することがわかった.また,そのスループット劣化を 防止するためには,従来TCPコネクションに必要とされる量の3倍から10倍の送信バッファが必要であることが明 らかとなった.
また,NECとの共同研究により,東京―大阪間の公衆インターネット回線を用いた,TCPプロキシ機構の実証実験 を行った.その結果,TCPプロキシ機構が実ネットワークにおいても有効であり,エンド端末のプロトコルやパ ラメータ設定を変更することなく従来手法に比べて高いデータ転送スループットを獲得できることを明らかにし た.また,TCPプロキシ間のTCPコネクションに高速TCPを用いることで,さらに高いスループットが得られるこ とがわかった.
[関連発表論文]
- Go Hasegawa, Yasuhiro Yamasaki, Masayuki Murata and Tutomu Murase, "TCP proxy mechanism in TCP overlay networks: Performance analysis and evaluation," submitted for publication, June 2006.
- Kana Yamanegi, Takayuki Hama, Go Hasegawa, Masayuki Murata, Hideyuki Shimonishi, and Tutomu Murase, "Performance evaluation of transport layer overlay mechanism in an actual internet environment," submitted for publication, July 2006.
3.1.9 超高速データ転送を実現するTCPの輻輳制御方式に関する研究
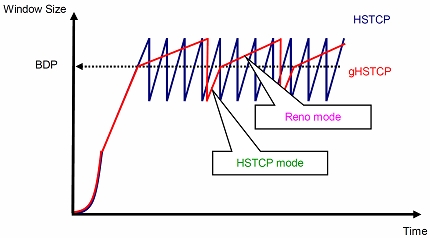
例えば,近年注目されているデータグリッドネットワーク,ストレージエリアネットワーク等においては,エン ド端末が1-10 Gbpsクラスの帯域を持つ高速ネットワークに直接接続され,データの取得・送出,データベース の更新,遠隔バックアップ等において,ギガバイトからテラバイト級のデータを高速に転送することが要求され る.このような高速データ転送を行う場合に,現在のインターネットにおいて標準的に用いられているTCP Reno バージョンを用いると,大きなリンク帯域を十分使う程度のスループットを得ることができないという問題が指 摘されている.この問題を解決するための一つの方法として,TCP Renoの輻輳制御方式を改変し,高いスループッ トを得ることができるHighSpeed TCPと呼ばれる方式が提案されているが,その性質はこれまで明らかになって おらず,特に従来のTCP Renoバージョンとの公平性に関しては考慮されていない.
そこで本研究では,HighSpeed TCPコネクションが従来のTCP Renoコネクションと同じリンクを共有する場合の, スループットおよび公平性に関して,数学的解析手法およびコンピュータ上のシミュレーションを用いて考察し ている.その結果,HighSpeed TCPは従来のTCP Renoに比べて非常に高いスループットを得ることができるが, システム条件によっては大量のパケット廃棄によってスループットが著しく低下し,リンク帯域を十分使う程度 のスループットを得ることができない場合があること,また,従来のTCP Renoと同じリンクを共有する場合, TCP Renoを用いたコネクションのスループットを大幅に低下させるため,両者の間の公平性を維持することがで きない等の問題点を持つことを明らかにしている.さらに本研究では,解析によって明らかになったHighSpeed TCPが持つ問題点を解決し,高いスループットを得るとともに,TCP Renoコネクションとの公平性を改善するTCP の輻輳制御方式の提案を行っている.提案方式の有効性はシミュレーションによって評価を行い,提案方式によっ て,従来のTCP Renoコネクション公平性を大幅に改善し,HighSpeed TCPに比べて最大で約50%のスループット向 上を実現できることを示している.
さらに本研究では,そのような高速TCPプロトコルではなく,GridFTPなどにおいて用いられている,通常のTCP コネクションを複数本並列的に用いることでデータ転送性能を向上させる並列TCP手法に着目し,その性能を数 学的解析により明らかにした.解析においては,並列に設定されるTCPコネクションが同期的に動作する場合, および非同期的に動作する場合の両方を考慮し,並列TCP手法によるデータ転送スループットの上限と下限を明 らかにした.その結果,理想的なTCP コネクション数はネットワークパラメータなどによって大きく変化し,そ の設定が困難であることが明らかとなった.また,高速TCPプロトコルと比較すると,ネットワーク環境の変動 に対する性質などの点で,並列TCP 方式が劣っていることを明らかにした.
[関連発表論文]
- Zongsheng Zhang, Go Hasegawa and Masayuki Murata, "Analysis evaluation of parallel TCP: Is it really effec-tive for long fat networks?," to appear in IEICE Transactions on Communications, April 2007.
- Zongsheng Zhang, Go Hasegawa and Masayuki Murata, "Reasons not to parallelize TCP connections for long fat networks," in Proceedings of SPECTS 2006, August 2006. [pdf] [ppt]
- 長谷川剛, 村田正幸, "高速・高遅延ネットワークのためのトランスポート層プロトコル," 電子情報通信 学会技術研究報告(IN2006-169), pp. 41-46, February 2007. [pdf]
3.1.10 エンドシステム/ネットワーク統合環境におけるTCPの高速・高 機能化に関する研究
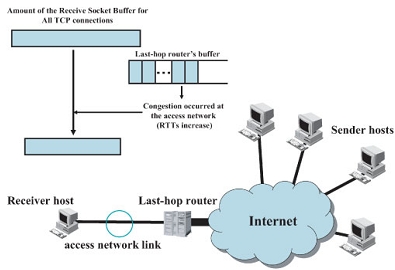
インターネットの急速な発展にともなうトラヒックの増大に対し,バックボーンネットワークでは広帯域化,高 速化が急速に進められている.一方,してアクセスネットワークの帯域はバックボーンネットワークに比べると 十分ではなく,特にユーザが複数のネットワークアプリケーションを同時に利用するような場合ではアクセスリ ンク帯域がボトルネックとなる.また,標準のTCP コネクションのスループットはRTT などのパラメータに大き く影響されるため,必ずしもユーザの意図した割合でアクセスリンク帯域がアプリケーション間で共有されない.
そこで本研究では,これらの問題点を解決し,ボトルネックとなるアクセスリンク資源を有効に活用するための アクセス資源管理方式を提案した.提案方式においては,まずユーザホストで全てのTCP コネクションに割り当 てられる受信バッファの総量を仮想的に調節することによって,アクセスリンクの輻輳を防止する.その後,各 TCP コネクションへの受信バッファの割り当てを,TCPコネクションの性質に基づいて決定する.シミュレーショ ンによる性能評価結果より,提案方式はデータ転送時間の減少,およびアクセスリンクでの輻輳の回避や遅延の 減少に大きな効果があり,従来方式と比較した場合,アクセスリンクの利用率を高く維持したまま, short-lived コネクションにおけるドキュメント転送の遅延を最大 90% 削減できることが明らかとなった.
[関連発表論文]
- Kazuhiro Azuma, Go Hasegawa and Masayuki Murata, "A study on a receiver-based management scheme of access link resources for QoS-controllable TCP connections," International Journal of Communication Systems, vol. 19, pp. 751-773, September 2006. [pdf]
3.2 フォトニックネットワークアーキテクチャに関する研究
近年の光伝送技術の発展には目覚しいものがあり,WDM(波長分割多重)技術によってネットワークの回線容量 は爆発的に増大してきた.しかし,光伝送技術とネットワーキング技術はおのおの別個の歴史を持ち,インター ネットに適した光通信技術の適用形態については明らかになっていないのが現状である.短期的には,高性能・ 高信頼光パスネットワークがその中心技術になると考えられ,長期的な解としてはフォトニックネットワーク独 自の通信技術を用いた大規模かつ分散制御型の光パスネットワークやフォトニックパケットスイッチネットワー クも十分に考えられる.本研究テーマでは,これらの点に着目した研究を進めている.
3.2.1 データ粒度可変光パスに関する研究(大阪大学大学院工学研究科北 山研究室との共同研究)
光符号を用いたパス設定には波長ルーティングに基づいたネットワークにおける固定的なデータ粒度に起因する 様々な問題を解決する可能性がある.本研究では,ひとつの波長に複数のパスを設定することにより利用率を向 上させることを目指し,光符号ラベルパスと光符号分割多重パスのデータ粒度を考慮して性能を明らかにする. 併せて,それぞれの手法を利用するための光クロスコネクトのアーキテクチャを示している.光符号ラベルパス にはオン-オフトラフィックモデルを適用し,光符号分割多重パスには多元接続干渉(MAI)を主な性能要因とする 近似モデルを用いて性能を解析した.その結果,提案した2種類の光パス設定手法にはそれぞれの適用領域があ ることがわかった.
[関連発表論文]
- Shaowei Huang, Ken-ichi Baba, Masayuki Murata and Ken-ichi Kitayama, "Variable bandwidth optical paths: Comparison between Optical Code-Labeled path and OCDM path," IEEE Journal of Lightwave Technology, pp. 3563-3573, October 2006.
3.2.2 光符号分割多重技術に基づくマルチ粒度光ネットワークにおける光 パスの設定手法に関する研究(大阪大学大学院工学研究科北山研究室との共同研究)
GMPLS (Generalized Multi-protocol Label Switching)は,光領域で,波長,波長群,ファイバの3種類のラベ ル交換パスを粒度として3階層のマルチ粒度光ネットワークを構成することにより,柔軟性が高く交換能力が高 いネットワークとして利用される.しかしながら,ユーザには波長を最小粒度として割り当てるため,波長より 細かい粒度での割り当てができず,帯域の十分な有効利用が図れないという問題点がある.そこで,本研究では, 近年活発に研究が進められている光符号分割多重(OCDM)技術を用い,データ交換の最小粒度としてOCDMパスを利 用し,1本の波長に複数のOCDMパスを収容することを考える.すなわち,従来の3階層交換ネットワークにOCDM交 換を加えた4階層マルチ粒度光ネットワークアーキテクチャを提案し,その上で光パスの設定手法を検討する. シミュレーションを行った結果,必要とする帯域が小さい場合など,あるパラメータ領域において,提案した4 階層方式は呼損率を低く抑えることができ有効であることを明らかにした.
[関連発表論文]
- Shaowei Huang, Ken-ichi Baba, Masayuki Murata and Ken-ichi Kitayama, "Architecture design and perform-ance evaluation of OCDM-based multi-granularity optical networks," OSA Journal of Optical Networking, pp. 1028-1042, December 2006.
- Shaowei Huang, Ken-ichi Baba, Masayuki Murata and Ken-ichi Kitayama, "OCDM-based fine multi-granularity optical path provisioning and its cross-connect design," in Proceedings of COIN-NGN2006, pp. 80-82, July 2006.
- Shaowei Huang, Ken-ichi Baba, Masayuki Murata and Ken-ichi Kitayama, "Evaluation of OCDM-switching and code conversion for all-optical end-to-end path provisioning in multi-granularity networks," in Proceedings of IEEE International Workshop on Guaranteed Optical Service Provisioning (GOSP) 2006, October 2006.
- Shaowei Huang, Ken-ichi Baba, Masayuki Murata and Ken-ichi Kitayama, "OCDM-based fine multi-granularity optical path provisioning and its performance evaluation," 電子情報通信学会 技術報告(PN2006-2), vol. 106, pp. 7-12, May 2006.
3.2.3 フォトニックインターネットにおける論理トポロジー設計手法に関 する研究
次世代インターネットの基盤ネットワークとして,WDM技術に基づいたIP over WDMネットワークが有望視されて いる.このようなIP over WDMネットワークのアーキテクチャの一つとして物理トポロジー上に光パスを設定す ることで論理トポロジーを構築し,その上でIPパケットを転送するアーキテクチャが考えられている.本研究で は, IP over WDM ネットワークにおいて,WDMネットワークの波長資源を効率的に使用し,トラヒックの変動に 対しても柔軟に収容することを目標とした統合経路制御手法を提案している.提案手法ではWDMネットワークの 波長利用状況に基づいて仮想リンクを用意し,仮想リンクを含むトポロジー上で経路制御を行う.シミュレーショ ンによる評価の結果,トラヒック変動がある場合,与えられたトラヒックデマンドに対して最適に設計された論 理トポロジーよりも,エンド・エンド間の平均遅延を抑えるとともに,約70%多くのトラヒックをネットワーク に収容できることがわかった.また,IP over WDMネットワークなど,広帯域,高速ネットワークを評価するた めに,流体モデルに基づくシミュレーション手法を用いることでシミュレーション終了時間を約1/500にするこ とが可能となった.
[関連発表論文]
- Yuki Koizumi, Shin'ichi Arakawa and Masayuki Murata, "An integrated routing mechanism for cross-layer traffic engineering in IP over WDM networks," to appear in IEICE Transactions on Communications, February 2007.
- Yuki Koizumi, "Cross-layer traffic engineering in IP over WDM networks," Master's thesis, Graduate School of Information Science and Technology, Osaka University, February 2006. [pdf] [ppt]
- Shinya Ishida, Shin'ichi Arakawa and Masayuki Murata, "Virtual Fiber Configuration for Dynamic Lightpath Establishment in large-scaled optical networks," Photonic Network Communications, vol. 12, pp. 87-98, July 2006. [pdf]
- Kang Xi, Shin'ichi Arakawa, and Masayuki Murata, "Virtual fully connected WDM network: A high-performance single-hop architecture for metropolitan area," Optical Switching and Networking, Vol. 3, No. 1, pp. 24-40, July 2006.
3.2.4 フォトニックネットワークにおけるオンデマンド型光パス設定に関 する研究
RSVP-TEは波長ルーティングに基づくGMPLSネットワークにおいて,光パスを設定・削除するためのシグナリング プロトコルである.RSVP-TEは光パスをソフトステート型の状態制御で管理する.ソフトステート型の状態制御 では,各ノードが制御ステートごとにタイマを設け,ステート維持のためのリフレッシュメッセージを受信する と,タイマをリセットする.リフレッシュメッセージの損失によりタイマがタイムアウトになると,制御ステー トは初期化され,予約されている資源は解放される.ソフトステート型のプロトコルはタイムアウトにより制御 ステートが初期化されるまで予約している資源を解放できない可能性があるため,ソフトステート型のプロトコ ルはハードステート型のプロトコルに比べ資源の利用効率が低いと考えられている.このため,制御メッセージ の再送など,ソフトステート型のプロトコルの性能を向上させるための拡張機能が考えられている.本研究では, いくつかのGMPLS RSVP-TEの動作をマルコフモデルを用いて記述し,それらの性能を解析した.その結果から, RSVP-TEにおける資源の利用効率は制御メッセージのロス率が低い場合はハードステート型のプロトコルと同等 であることが分かった.また,制御メッセージの再送の効果を調べ,場合によっては制御メッセージを再送する ことが資源の利用効率を低下させることを示した.
[関連発表論文]
- Masatoshi Ohashi, Shin'ichi Arakawa and Masayuki Murata, "Implementation and evaluation of fast lightpath setup method in wavelength-routed WDM networks," in Proceedings of SPIE APOC2006, vol. 6354, pp. 63541V-1 - 63541V-9, September 2006. [pdf] [ppt]
- Shinya Ishida, Shin'ichi Arakawa and Masayuki Murata, "Analyses of soft-state signaling proto-cols in GMPLS-based WDM networks," submitted for publication, July 2006.
- Shinya Ishida, Shin'ichi Arakawa and Masayuki Murata, "Performance analysis of soft-state lightpath management in gmpls-based wdm networks," in Proceedings of Third International Conference on Broadband Communications, Networks, and Systems (Broadnets 2006), (San Jos'e, CA), October 2006. [pdf] [ppt]
3.2.5 高信頼フォトニックネットワークに関する研究
本研究では,波長ルーティングネットワークにおける,ある特定の領域におけるOXCの複数障害(面障害と呼ぶ) に対する障害回復手法を提案する.提案手法は障害部分を囲い込む閉路を動的かつ局所的に構成し,その閉路に 沿って障害により切断された光パスを迂回させる.シミュレーション結果から,面障害の規模が大きくない場合 はパスリストレーション手法に比べて高速にほぼ全ての光パス接続を回復できることが分かった.提案手法はま た,障害回復時の制御メッセージ量の増加を抑えることにより,制御プレーンの輻輳を回避している.
[関連発表論文]
- Shinya Ishida, Shin'ichi Arakawa and Masayuki Murata, "Local recovery from massive failures in large-scaled WDM networks," submitted for publication, May 2007.
- Shinya Ishida, "A Study on Flexible, Reliable, and Scalable Wavelength-Routed Optical Networks". PhD thesis, Graduate School of Information Science and Technology, Osaka University, January 2007 [pdf] [ppt]
3.2.6 小容量バッファを持つフォトニックパケットスイッチネットワーク に関する研究
パケットを光領域でスイッチングやフォワーディングを行うフォトニックパケットスイッチは,高速インターネットのためのインフラストラクチャを構成する重要な要素技術である.しかし,フォトニックパケットスイッチでは光領域におけるパケット蓄積技術が確立されていないことから,パケット競合の回避のために光ファイバによる固定長の遅延線(FDL; Fiber Delay Line) が考えられている.フォトニックパケットスイッチ実現のためには多くの課題を解決することが必要となるが,その一つが光パケットを蓄積するバッファの容量である.本研究では,小容量バッファを持つフォトニックパケットスイッチによって構成されたネットワークを対象とし,ネットワークのスループットを向上させるための手法を検討している.関連発表論文では,エッジノード間にXCPに基づくフローコントロール機構を導入し,エッジノードにおいてFDLによって生じるパケット間空き領域情報を考慮したパケット送信間隔制御を行うことで必要FDL長を大幅に抑えられることを明らかにしている.
[関連発表論文]
- Onur Alparslan, Shin'ichi Arakawa and Masayuki Murata, "Performance of paced and non-paced transmission con-trol algorithms in small buffered networks," in Proceedings of the 11th IEEE Symposium on Computers and Communications (ISCC'06), (Sardinia, Italy), pp. 115-122, June 26-29, 2006. [pdf] [ppt]
- Onur Alparslan, Shin'ichi Arakawa, Masayuki Murata, "Rate-based paced XCP for small buffered optical packet switched networks," 電子情報通信学会技術研究報告, pp. 35-40, May 2006.
- Onur Alparslan, Shin'ichi Arakawa, Masayuki Murata, "A comparative study of switch architectures for small-buffered optical packet switched networks," 電子情報通信学会技術研究報 告, pp. 167-172, January 2007.
3.2.7 IP+光統合網上のマルチレイヤトラヒックエンジニアリングにおけ るトラヒック推定誤差の影響とその改善法に関する研究(NTTネットワークサービスシステム研究所との 共同研究)
現在,情報通信インフラとしてのIP網の安定化や高効率化,高信頼化などを実現するために,IP網に光パス網を 組み合わせたIPと光の統合網の研究開発が世界規模でなされている.IP+光統合網上でトラヒックを効率的に収 容する方法として,光パスによって構築される論理トポロジー (VNT) を動的に再構成する手法の研究が進めら れている.VNT を適切に再構成するためには,対地間のトラヒック量を把握することが必須である.しかしなが ら,ネットワークの規模が大きくなるとともに,すべての対地間トラヒック量を測定することは困難となる.
本研究では,リンク負荷などの一部の測定情報から対地間トラヒック量を推定するトラヒックマトリクス推定手 法に関する検討を行っている.特に,従来のVNT 再構成手法では,その入力となるトラヒックマトリクスは正確 に測定されたものであると仮定をおいているが,実際は上述のような理由により推定されたトラヒックマトリク スを用いるため,推定誤差の影響を大きく受けることになる.
そこで本研究では,推定手法により得たトラヒックマトリクスを用いてトラヒックエンジニアリングを行った際 に,推定誤差がネットワーク性能にどのような影響を与えるかについての評価を行った.その結果,つい呈され たトラヒックマトリクスを用いてIP+光マルチレイヤトラヒックエンジニアリングを実施した場合,IP および光 レイヤにそれぞれ単一によるトラヒックエンジニアリングよりも良い性能を示すものの,一方で推定誤差による 性能低下の影響をより大きく受けることが明らかとなった.そこで,推定誤差を減少させることを目的として, トラヒックの経路の変更に基づいたトラヒックマトリクスの再推定手法を提案した.そして,推定誤差が大きい 箇所を再推定することができれば,マルチレイヤトラヒックエンジニアリングの性能を向上させることができ, ネットワークに収容できるトラヒック量を増加させられることを示した.
本研究ではさらに,トラヒックマトリクス推定の誤差に関する影響を考慮に入れた新しいVNT再構成の手法をし た.提案手法では,VNT再構成を複数ステージに分割し,前ステージでの測定情報を推定に反映させることによ り,推定誤差を削減しつつVNT再構成を行う.また,提案手法では,各ステージで追加・削除される光パスの本 数に制約をもうけることにより,推定誤差の影響を受ける範囲を制限したVNT再構成を行う.シミュレーション を用いた性能評価により,提案手法が誤差を削減し,トラヒックエンジニアリングへの誤差の影響を緩和できる ことを示した.
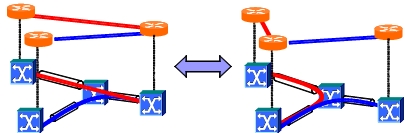
[関連発表論文]
- Yuichi Ohsita, Takashi Miyamura, Shin'ichi Arakawa, Shingo Ata, Eiji Oki, Kohei Shiomoto and Masayuki Murata, "Gradually reconfiguring virtual network topologies based on estimated traffic matrices," to be pre-sented at IEEE INFOCOM 2007 Mini-Symposium, May 2007.
- Yuichi Ohsita, Takashi Miyamura, Shin'ichi Arakawa, Shingo Ata, Eiji Oki, Kohei Shiomoto, Shigeo Urushi-dani and Masayuki Murata, "Impact of traffic estimation on IP and optical multilayer TE," 電子情報通信学会技術研究報告(PN2006-11), pp. 7-12, August 2006. (PN若手研究賞) [pdf] [ppt]
- Yuichi Ohsita, Takashi Miyamura, Shin'ichi Arakawa, Shingo Ata, Eiji Oki, Kohei Shiomoto and Masayuki Murata, "Gradually reconfiguring virtual network topologies based on estimated traffic matrices," 電子情報通信学会技術研究報告(PN2006-38), pp. 67-72, October 2006. [ppt] [pdf]
- 大下裕一, 宮村崇, 荒川伸一, 阿多信吾, 大木英司, 塩本公平, 村田正幸, "段階的 VNT 再構成時におけ るトラヒック推定精度向上のための検討," 電子情報通信学会PN 研究会, March 2007. [pdf]