1) ネットワークサービスアーキテクチャに関する研究
1.1 適応型QoS制御技術に関する研究
1.1.1 多人数参加型P2Pテレビ会議システムのための論理網構築手法
P2P技術を利用したテレビ会議システムの多くは高々10名程度の参加者にしか対応していない.一方,全国に支店のある企業の支店長会議,遠隔講義,コミュニティサービスなどにおいては百人〜千人規模のテレビ会議の開催が望まれている.動画像を同時に多数の参加者に効率的に配信する技術としてはALM (Application Level Multicast)などがあるが,一対多の配信を対象としており,参加者相互の対話的なやりとりについては考慮されていない.
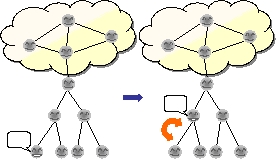
そこで本研究では,十数名程度の活発な発話者を含む千人規模のテレビ会議を実現するための,P2P技術を用いたテレビ会議データ配信ネットワークの構築手法を提案している.提案手法では,多人数の参加する会議においても活発に議論にする参加者は同時に高々数名程度であることに着目し,それら発話者間の遅延を小さくすることにより円滑な会議を達成する.提案手法は,配信ネットワーク構築機構,配信ツリー再構成機構,障害回復機構からなる.階層的な配信ネットワークを構築することによって参加者数に対する拡張性を高めるとともに,ノードの利用可能帯域や発話量に応じて配信ネットワークを動的に再構成することにより,発話者間,参加者間の遅延を抑える.シミュレーションによる評価の結果,千人規模のテレビ会議において,配信ネットワークの再構成によって,発話者間の遅延を40ミリ秒から70ミリ秒程度に抑えることができることを示した.
[関連発表論文]
- Hideto Horiuchi, Naoki Wakamiya and Masayuki Murata, "Proposal and evaluation of a network construction method for a scalable P2P video conferencing system," in Proceedings of the International Conference on Information Networking (ICOIN 2007), (Estoril), January 2007. [pdf] [ppt]
- Hideto Horiuchi, Naoki Wakamiya and Masayuki Murata, "A network construction method for a scalable P2P video conferencing system," in Proceedings of the IASTED European Conference on Internet and Multimedia Systems and Applications (EuroIMSA 2007), (Chamonix), March 2007. [pdf]
- 堀内英斗, 若宮直紀, 村田正幸, "多人数参加型P2P テレビ会議システムにおける論理網構築手法の提案と評価," 電子情報通信学会技術研究報告 (IN2006-35), pp. 1-6, July 2006. [pdf] [ppt]
- 堀内英斗, 若宮直紀, 村田正幸, "多人数参加型P2P テレビ会議システムのための論理網構築手法の提案と 評価," 電子情報通信学会技術研究報告, March 2007. [pdf]
- Hideto Horiuchi, "A construction method of an overlay network for scalable P2P video conferencing systems," Master's thesis, Graduate School of Information Science and Technology, Osaka University, February 2007. [pdf] [ppt]
1.2 分散サービス拒否攻撃に対する防御システムに関する研究 (NTTネットワークサービスシステム研究所との共同研究)
近年頻繁に見られるようになったサービス拒否 (DoS: Denial of Service) 攻撃は,インターネット上に存在する特定のサイトに対して大量のパケットを送 りつけることでそのサイトで提供されているサービスを利用できなくする,もしくはそのサービスの品質を著しく低下させるような行為を指す.DoS 攻撃は 近年多様化・分散化し,その威力は増すばかりである.その中でも分散化した攻撃は特に DDoS (Distributed DoS) 攻撃と呼ばれており,現存するプロトコ ルにのっとったものであるため,その効果的な防御策が確立されていない.特に,TCP の仕様を悪用したSYN Flood 攻撃は,簡単な方法で容易にサーバを停 止状態にできることから,現在最も多く利用されており,深刻な社会的問題となっている.本研究では,特に広く分散された攻撃ノードからの SYN Flood を 対象とし,その分散防御機構ならびに検出メカニズムに関する検討を行っている.
DDoS 攻撃に対する根本的な防御として,攻撃元を特定したのち,エッジルータにおいてフィルタリング等を行うことが有効である.しかし,既存の攻撃元特 定手法では,ルータの大規模な置き換えが必要となるものや,攻撃元と正常な通信相手の区別が難しい等の問題があり,広く利用されていないのが現状であ る.本研究では,既存のルータを用いて実現可能であり,トラヒック増加の原因となる送信元を検出する新たな攻撃元検出手法を提案する.提案手法では, SNMP などによる定期的なルータからトラヒック観測情報を収集し,各送信元宛先間のトラヒック変化量を推定する.そして,その推定結果をもとに,トラヒッ ク増加の原因となる攻撃元の特定を行う.シミュレーションにより,提案手法が正確に攻撃元を特定することを確認した.
[関連発表論文]
- Yuichi Ohsita, Shingo Ata and Masayuki Murata, "Detecting distributed Denial-of-Service attacks by analyzing TCP SYN packets statistically," IEICE Transactions on Communications, vol. E89-B, pp. 2868-2877, October 2006. [pdf]
- Yuichi Ohsita, Shingo Ata and Masayuki Murata, "Identification of attack nodes from traffic matrix estimation," submitted for publication, September 2006.
1.3 オーバレイネットワークアーキテクチャに関する研究
1.3.1 オーバレイネットワーク共生環境
物理網上に構築されたオーバレイネットワークはそれぞれのアプリケーションレベルのQoSの向上のため, 利己的にトラヒック制御,経路制御,トポロジー制御を行う.このような利己的な振る舞いは物理網を介して他 のオーバレイネットワークに影響を与え,それらネットワークの利己的な制御を引き起こすため,結果としてネッ トワーク全体の性能が劣化する.本研究では,生物の共生メカニズムに着想を得て,オーバレイネットワークの 共生の仕組みを提案している.ノードは自律分散的に振る舞い,オーバレイネットワークに参加,離脱するとと もに,他のネットワークに対して論理リンクを接続,切断する.互いに利する論理リンクは維持されるため,双 利関係にあるオーバレイネットワーク間には多くの論理リンクが設定されるようになり,いずれ一つとなる.こ のようにしてよりよいオーバレイネットワークが自己組織的に構築されることとなる.
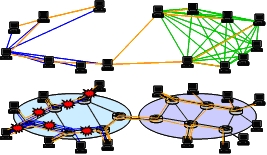
本研究では,異なるモデルに従って成長するネットワークの持つ特性(次数分布)を解析的に明らかにし,ま た,それらのネットワークの結合の効果をメッセージ到達率,負荷増加度によって評価した.その結果,優先的 接続(Preferential Attachment)によって成長するネットワークを次数の高いノードによって結合することに より,最も高いメッセージ到達率を獲得できることを示した.また,生物の共生の仕組みを説明する数学モデル を適用することにより,ネットワークが共生するための条件について分析した.その結果,単一のネットワーク では存在できないが他のネットワークとの共生によって生存が可能となるパラメータ領域が存在することを示し た.さらに,ピュア型・ハイブリッド型P2Pファイル共有ネットワークを対象に,ピアを介した検索・応答メッ セージのやりとりによる協調の仕組みについて検討し,ファイル発見率や発見数,ファイル検索遅延などのアプ リケーションレベルのQoSが向上することをシミュレーションによって示した.
[関連発表論文]
- Junjiro Konishi, Naoki Wakamiya and Masayuki Murata, "Design and evaluation of a cooperative mechanism for pure P2P file-sharing networks," IEICE Transactions on Communications, Special Section on Networking Technologies for Overlay Networks, vol. E89-B, pp. 2319-2326, September 2006. [pdf]
- Hongye Fu, Naoki Wakamiya and Masayuki Murata, "A cooperative mechanism for hybrid P2P file-sharing networks to enhance application-level QoS," IEICE Transactions on Communications, Special Section on Net-working Technologies for Overlay Networks, vol. E89-B, pp. 2327-2335, September 2006. [pdf]
- Naoki Wakamiya, Junjiro Konishi and Masayuki Murata, "A cooperative mechanism of pure P2P file-sharing networks to improve application-level QoS," in Proceedings of SPIE ITCom 2006, vol. 6387, (Boston), pp. 06-1-06-11, October 2006. [pdf] [ppt]
- Naoki Wakamiya and Masayuki Murata, "Overlay network symbiosis: Evolution and cooperation," in Pro-ceedings of First International Conference on Bio-Inspired Models of Network, Information and Computing Systems (Bionetics 2006), (Cavalese, Italy), December 2006. [pdf] [ppt]
- Naoki Wakamiya and Masayuki Murata, "Bio-inspired analysis of symbiotic networks," to be presented at 20th International Teletraffic Congress (ITC-20), (Ottawa, Canada), June 2007.
1.3.2 アトラクタ選択モデルにもとづくマルチパス経路制御
オーバレイネットワークやアドホックネットワークでは,時々刻々と変化する通信状態に応じて送受信ノード間 で適切な経路を選択し,通信を行う.オーバレイネットワークにおいては他のオーバレイネットワークとの競合, アドホックネットワークでは無線通信環境の変化といった予測できない事象によってネットワークの特性が動的 に激しく変動する.このようなネットワークにおいて経路制御の最適化戦略を構築することは困難であるため, 自律的で適応的な経路制御が必要となる.
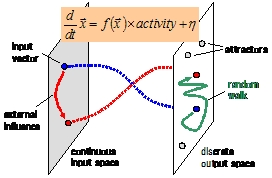
本研究では,環境変化に対する生物システムの適応的な振る舞いをモデル化したアトラクタ選択モデルを応用す ることにより,自律分散的で通信状態の変化に対する適応性のある経路制御手法を提案している.経路の選択確 率は,選択した経路のよさとノイズによって定義される偏微分方程式によって決定される.遅延が小さいなど選 択した経路が適切である場合にはノイズの影響は小さいが,不適切な経路が選ばれた場合,あるいは,通信状態 の変動によって経路の品質が低下した場合には,ノイズの影響が大きくなり,ランダムによりよい解(経路)を 探索することとなる.シミュレーション評価により,通信状態の変化に対して適応的に経路を選択し,安定した 通信が可能であることを示した.
[関連発表論文]
- Kenji Leibnitz, "A biologically-inspired approach for self-adaptive ad-hoc network routing," Jeju International Ubiquituous Computing Conference 2006 (Jeju IUCC 2006), April 2006. [pdf]
- Kenji Leibnitz, Naoki Wakamiya and Masayuki Murata, "Self-adaptive ad-hoc/sensor network routing with attractor-selection," in Proceedings of IEEE GLOBECOM, (San Francisco, CA), November 2006. [pdf] [pdf]
- Kenji Leibnitz, "On biologically-inspired control methods in modern communication networks," Operations Research Society of Japan - Queuing Systems, November 2006. [pdf]
1.3.3 物理網特性を考慮したP2Pネットワーク構築手法
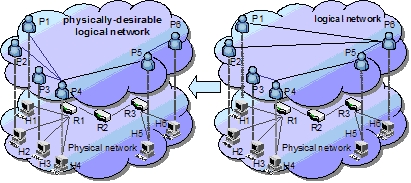
物理的に遠いピアが論理網上で隣接するなど,物理網構造と乖離した論理網を構築した場合,例えばP2Pファイ ル共有アプリケーションにおいては,冗長なトラヒックによりファイル検索が物理網に与える負荷が高くなる, 最も物理的に近いファイル所有者を知るために多くの応答メッセージの受信を待たなければならない,などの問 題が発生する.
本研究では,ピュア型P2Pファイル共有アプリケーションにおいて,物理網構造を考慮することにより高速な ファイル検索・取得を実現するためのP2Pネットワーク構築手法を提案している.提案手法では,ブートストラッ ピングノードから知ったピアのうち,物理的に近く次数の高いピアを接続先として選択する.このことにより, 物理的に近いピア同士が接続されたパワー則に従うP2Pネットワークを構築することができる.その結果,効率 よくファイルが検索でき,また,より早く応答メッセージを送信ピアが物理的にも近いピアとなるため,即座に ファイル取得を開始できる.さらに,ネットワーク構造をよりよくするため,より近く,次数の高いピアへのリ ンクの切り替えを試みる.また,ピア消失に対してはリンクを補完することによってネットワークの構造を維持 する.現実の物理網モデルを用いたシミュレーションにより,BAモデルや他手法と比較して検索効率がよく,障 害にも強い,物理網特性を考慮した論理網を構築できることを示した.
[関連発表論文]
- Masahiro Sasabe, Naoki Wakamiya, and Masayuki Murata, "LLR: A Construction Scheme of Low-Diameter, Location-Aware, and Resilient P2P Network," in Proceedings of The First International Mobility, Collabora-tive Working, and Emerging Applications (MobCops2006), (Atlanta), November 2006. [pdf] [ppt]
1.3.4 P2Pファイル共有システムにおける進化ゲーム理論を用いたキャッシングアルゴリズム
P2P ファイル共有システムでは,それぞれのノードが所有するファイルを複数のノード間で共有する.複数の ノードが同一ファイルをキャッシュし,他のノードに提供することによって,低遅延でファイル可用性の高いファ イル共有が期待できる.しかしながら,ファイルのキャッシングには処理負荷,ストレージ資源などのコストが 生じる.そのため,ノードが自身の利得だけにもとづき利己的に振る舞うと,十分にファイルがキャッシュされ ず,特に人気の低いファイルがシステムから消失するなどの問題が発生する可能性がある.
本研究では,ノードの自律的,利己的な振る舞いによってシステム全体で適切なキャッシングが行われる機構の 実現を目指す.そのため,利己的な振る舞いのモデルとして進化ゲーム理論を用い,ノードの振る舞いがシステ ム全体のダイナミクスに与える影響について検証した.進化ゲーム理論では,プレイヤはより多くの利得を得た 対戦相手の戦略を模倣することにより,自身の利得の向上を図る.シミュレーションやモデルにもとづく議論の 結果,キャッシングに対するコストと需要のモデルによっては,進化ゲーム理論のもとでノードが利己的に振る 舞ったとしても,ファイルがシステムから消失することのない,効果的なファイル共有が実現可能であることを 示した.
[関連発表論文]
- Masahiro Sasabe, Naoki Wakamiya, and Masayuki Murata, "A Caching Algorithm using Evolutionary Game Theory in a File-Sharing System," submitted for publication, February 2007.
- 笹部昌弘, 若宮直紀, 村田正幸, "ファイル共有システムにおける進化ゲーム理論を用いたキャッシングア ルゴリズム," 電子情報通信学会技術研究報告(IN2006-154), pp. 97-102, January 2007. [pdf]
1.3.5 オーバレイルーティングに起因するネットワークただ乗り問題に関する研究(NEC社との共同研究)
オーバレイネットワークには,エンドホスト間のTCP スループットや遅延時間,IP ネットワークレベルあるい はオーバレイネットワークレベルのホップ数などのネットワーク性能を指標として,トラヒック制御を行うもの が存在する.また,特定のアプリケーションを前提とせず,トラヒックのルーティングそのものを目的(アプリ ケーション) とするオーバレイネットワークも登場しつつある.オーバレイルーティングを行うことによって, 通常のIP ルーティングに比べて,利用するユーザにとってのネットワーク性能(スループットや転送遅延時間な ど) が改善することが明らかとなっている.これは,オーバレイルーティングとIP ルーティングではルーティ ングに用いるポリシーが大きく異なることに起因している.しかし,逆にオーバレイルーティングが,IP ルー ティングを司るISP に悪影響を及ぼすことが考えられる.これは,主にISP が持つ他ISP との接続リンクの課金 構造が原因で発生する.ISP が上位ISP に対して持つトランジットリンクは,通過するトラヒック量の最大値に 応じて通常課金される.一方,ピアリングリンクはコストは回線そのものの維持コスト(通常ピアリングするISP で折半される) を除いてほとんど発生しない.ISP が行うIP ルーティングはこのコスト構造の違いを考慮して 行われており,ピアリングリンクにはピアリング関係にある両ISP を起点・終点とするトラヒックのみが通過す る.一方,アプリケーションレベルで行われるオーバレイルーティングはこのようなISP の都合を考慮せず,ネッ トワーク性能やアプリケーションの要求のみに基いて行われるため,ISP が前提としているコスト構造を無視し たトラヒックが発生することが考えられる.
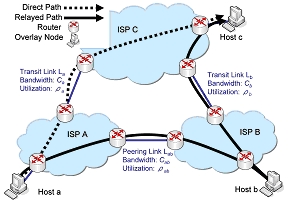
本研究ではこの問題をオーバレイルーティングによるネットワークただ乗り問題と呼び,それがISP にとって 無視できない問題であることを指摘した.まず,本研究において対象とするただ乗り問題の定義を行い,ISP に とって深刻な問題となり得ることを指摘した.また,オーバレイルーティングがルート選択の際に用いるパスの 性能指標として空き帯域(利用可能帯域) およびノード間ラウンドトリップ時間を考え,それぞれを用いた場合 に,他のノードを中継してトラヒックが運ばれる条件およびそのトラヒック量に関する定式化を行った.また, 研究用大規模オーバレイネットワークであるPlanetLabで得られている参加ノード間の計測データを用いて,ネッ トワーク全体でどの程度のトラヒックがただ乗り経路によって運ばれる可能性があるかを試算し,それが無視で きない量であることを指摘した.
[関連発表論文]
- Go Hasegawa and Masayuki Murata, "Free-riding traffic problem in routing overlay networks," submitted for publication, February 2007.
- 長谷川剛, 小林正好, 村田正幸, 村瀬勉, "オーバレイルーティングに起因するネットワークただ乗り問題 に関する一検討," 電子情報通信学会技術研究報告(IN2006-136), pp. 133-138, December 2006. [pdf] [ppt]
1.4) λコンピューティング環境の構築に関する研究
近年,ネットワーク接続された複数の計算機を用いて大規模な科学技術計算を行うグリッド計算に関する研究開 発が盛んに行われている.グリッド計算環境で分散計算を実行する場合,現状ではノード計算機間の通信には TCP/IPが用いられているが,TCP/IPを用いたパケットを単位としたデータ交換では,パケット損失やパケット処 理に要するオーバーヘッドの影響が大きく,大規模計算で必要な大量データの共有や交換を行うには十分な性能 を得ることは困難である.そこで各ノード計算機に光ファイバを直結し,さらに近年研究開発が活発に行われて いるWDM (Wavelength Division Multiplexing)技術を適用して波長パスをノード計算機間の高速な通信チャネル として活用するλコンピューティング環境を提案している.すなわち,波長パスを利用することにより,ユーザ に対して高速かつ高信頼な通信パイプを提供することが可能になり,さらに,波長パスを用いて,例えば仮想的 にノード計算機をリング状に接続することによって,分散計算を行うノード計算機間でのデータ交換,共有がで きるようになる.現在,λコンピューティング環境の実現形態として,WDM技術に基づくフォトニックネットワー クを用いてグリッド計算環境を構築している.
1.4.1 λコンピューティング環境におけるOpenMPライブラリの実装と評価
本研究では,λコンピューティング環境を実現するひとつの形態としてWDM技術に基づくAWG-STARシステムを用 いることとし,共有メモリを用いた並列計算プログラミングAPIであるOpenMP の設計と実装を行っている.我々 は既存のOpenMPコンパイラであるOMPiに基づき,OMPiおよびそのランタイムライブラリをAWG-STARシステム上で 並列計算を可能とするように修正することによりAWG-STARシステム向けコンパイラを作成している.具体的には, AWG-STARシステムの共有メモリを用いて計算データを共有するようにコンパイラを修正し,AWG-STARシステムで 接続された複数のノード計算機を用いて並列処理を行うようにランタイムライブラリを修正している.さらに, 並列計算を行う際に必要となるライブラリの同期プリミティブおよびデータ共有機構を設計し,AWG-STARシステ ム上で実装している.
また,我々の計算環境の性能をベンチマークアプリケーション,ならびにOpenMPアプリケーションを実行させる ことによって評価している.しかしながら,現在のAWG-STARシステムでは既存の計算環境と同等の性能は達成で きなかった.これは,共有メモリのアクセス速度が十分でなくボトルネックとなり,計算性能を低下させている ためである.
現在のAWG-STARシステムではローカルメモリに比べて低速なPCIバスを介して共有メモリにアクセスしなければ ならない.そのため,現在,NTTフォトニクス研究所では共有メモリアクセス速度を改善した次期AWG-STARシス テムを開発中であり,この次期システムでの性能改善の効果について見積もりを行った.その結果,次期 AWG-STARシステムでの改善は計算性能の改善に非常に効果のあることが分かった.さらに,次期システムための 同期プリミティブと,共有メモリの仮想化も同時に提案した.
[関連発表論文]
- Keigo Goda, Mai Imoto, Ken-ichi Baba, Noriyuki Fujimoto, Masayuki Murata, "Design and implementation of OpenMP library for λ computing environment," submitted for publication, February 2007.
- 井本舞,合田圭吾,馬場健一,村田正幸, " コンピューティング環境におけるOpenMPライブラリのための データ共有機構の設計," 電子情報通信学会技術研究報告(PN2006-28), vol. 106, pp. 19-24, October 2006. [pdf] [ppt]
- 合田圭吾, 井本舞, 藤本典幸, 馬場健一, 村田正幸, " コンピューティング環境におけるOpenMPライブラ リの設計と実装," 電子情報通信学会技術研究報告(PN2006-40), vol. 106, pp. 5-8, December 2006. [pdf] [ppt]
- 井本舞,合田圭吾,馬場健一,村田正幸, " コンピューティング環境におけるOpenMPアプリケーションに よる共有メモリシステムの評価," March 2007. [pdf]
- Keigo Goda, "Design and implementation of OpenMP compiler for computing environment," Master's thesis, Graduate School of Information Science and Technology, Osaka University, February 2007. [pdf] [ppt]
- Mai Imoto, "Design and implementation of synchronization primitives for ?computing environment," Master's thesis, Graduate School of Information Science and Technology, February 2007. [pdf] [ppt]
1.4.2 光リングネットワークにおけるλコンピューティング環境に適した共有メモリアーキテクチャの評価
λコンピューティング環境における共有メモリアーキテクチャでは,従来のマルチプロセッサシステムとは異な り計算機が広域に展開しているため,ネットワーク特性がその性能に大きな影響を与える.以前の研究において, λコンピューティング環境における共有メモリアーキテクチャのモデル化を行い,ネットワークやキャッシュ一 貫性制御のための処理がシステムの性能にどのような影響をあたえるかを解明し,どのような共有メモリアーキ テクチャが,λコンピューティング環境に適しているかについて報告されている.この報告において対象とされ たネットワークモデルは単一波長のリングモデルとフルメッシュモデルである.単一波長モデルにおいては,各 ノード計算機での処理時間等の影響が大きくなり,フルメッシュモデルではハードウェアの制約上,実現が難し いと考えられる.
そこで,本報告では,λコンピューティング環境において波長数やハードウェアの制約を考慮した実現可能なリ ングネットワークにおける共有メモリアーキテクチャを提案し,その性能を評価する.具体的には,リングネッ トワークにおいて複数波長を用いてデータ転送やキャッシュ一貫性制御を行う方式の設計を行い,制御にかかる 遅延時間を求め,セミ・マルコフ過程を用いて解析を行った.その結果,共有メモリアクセス頻度が大きい場合 など,大きな性能向上が得られるパラメータ領域が存在することが明らかになった.